Introduction
팝업을 추가하면 구매율이 정말 증가할까요? 혹은 팝업이 오히려 사용자 경험을 방해해 구매율을 떨어뜨릴 가능성은 없을까요? 이를 객관적으로 평가하는 효과적인 방법은 A/B 테스트입니다.
A/B 테스트는 모든 사용자에게 팝업을 무작정 보여주기보다는, 일부 사용자에게만 노출하여 그 효과를 비교 분석하는 방식입니다. 이를 통해 팝업이 긍정적인 영향을 미치는지 데이터 기반으로 검증할 수 있습니다.
이번 글에서는 A/B 테스트를 설정하고 수행하는 구체적인 방법을 알아보겠습니다.
A/B 테스트 설정: actionSpeak 태그 설정하기
GTM과 actionSpeak 활용하여 고객에게 말 걸기에서는 재방문 사용자에게 할인 상품을 추천하는 팝업 예시를 다뤘습니다. 이번에는 해당 팝업에 대해 A/B 테스트를 수행해 보겠습니다.
-
GTM(Google Tag Manager)에서 작업할 컨테이너에 들어갑니다.
-
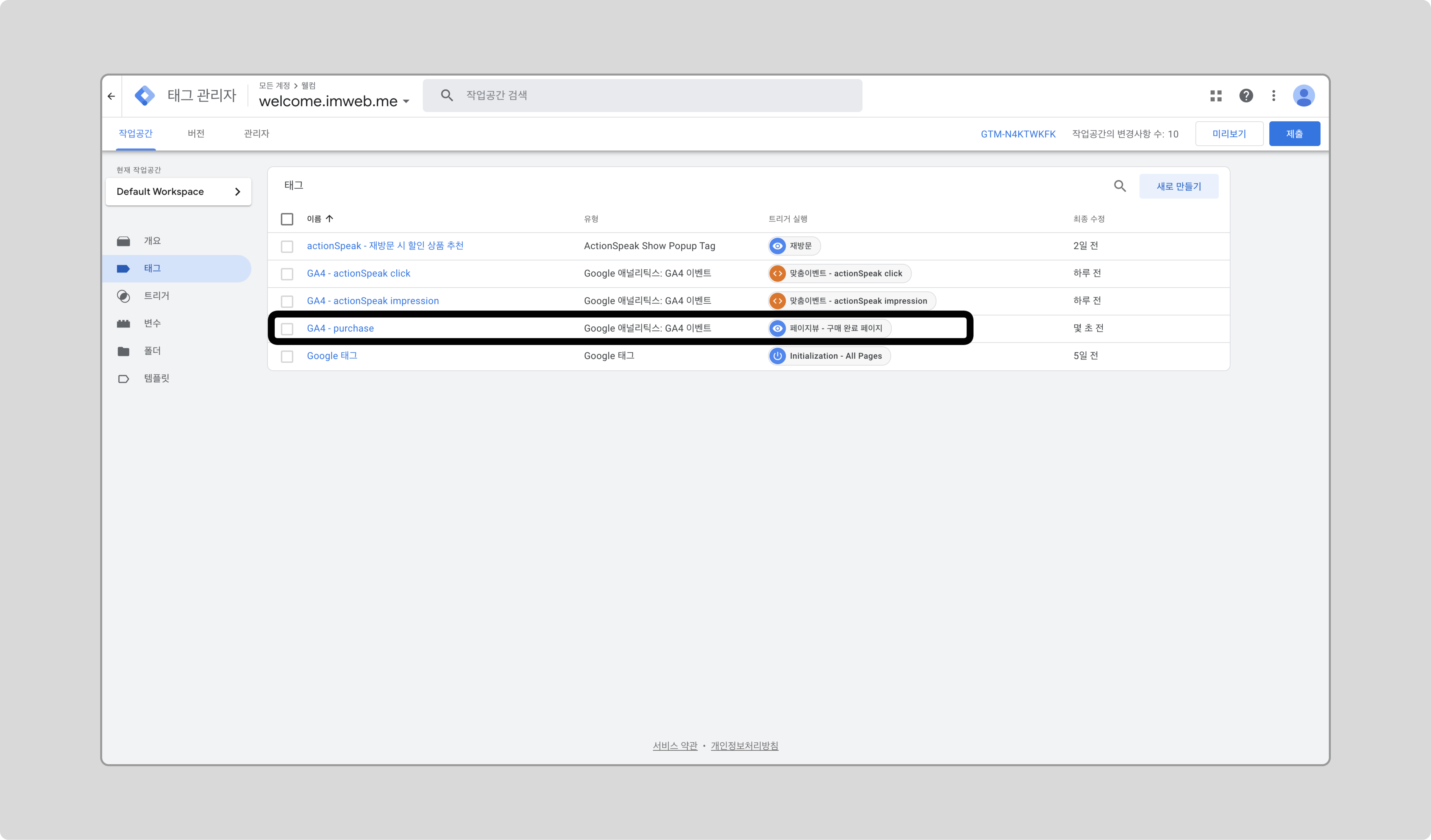
actionSpeak 태그를 클릭합니다.
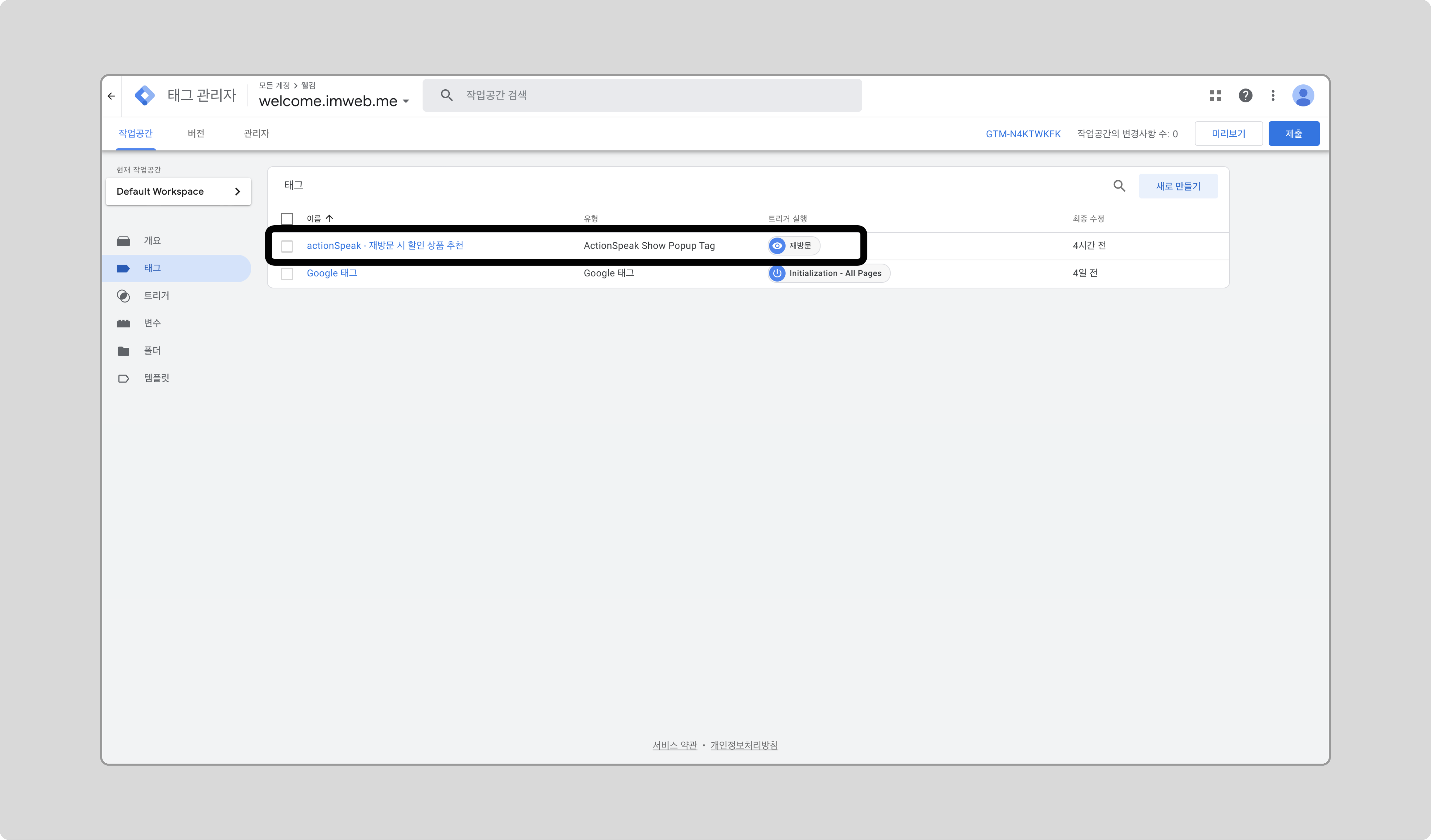
-
‘A/B 테스트’ 체크박스를 체크하고 저장합니다.
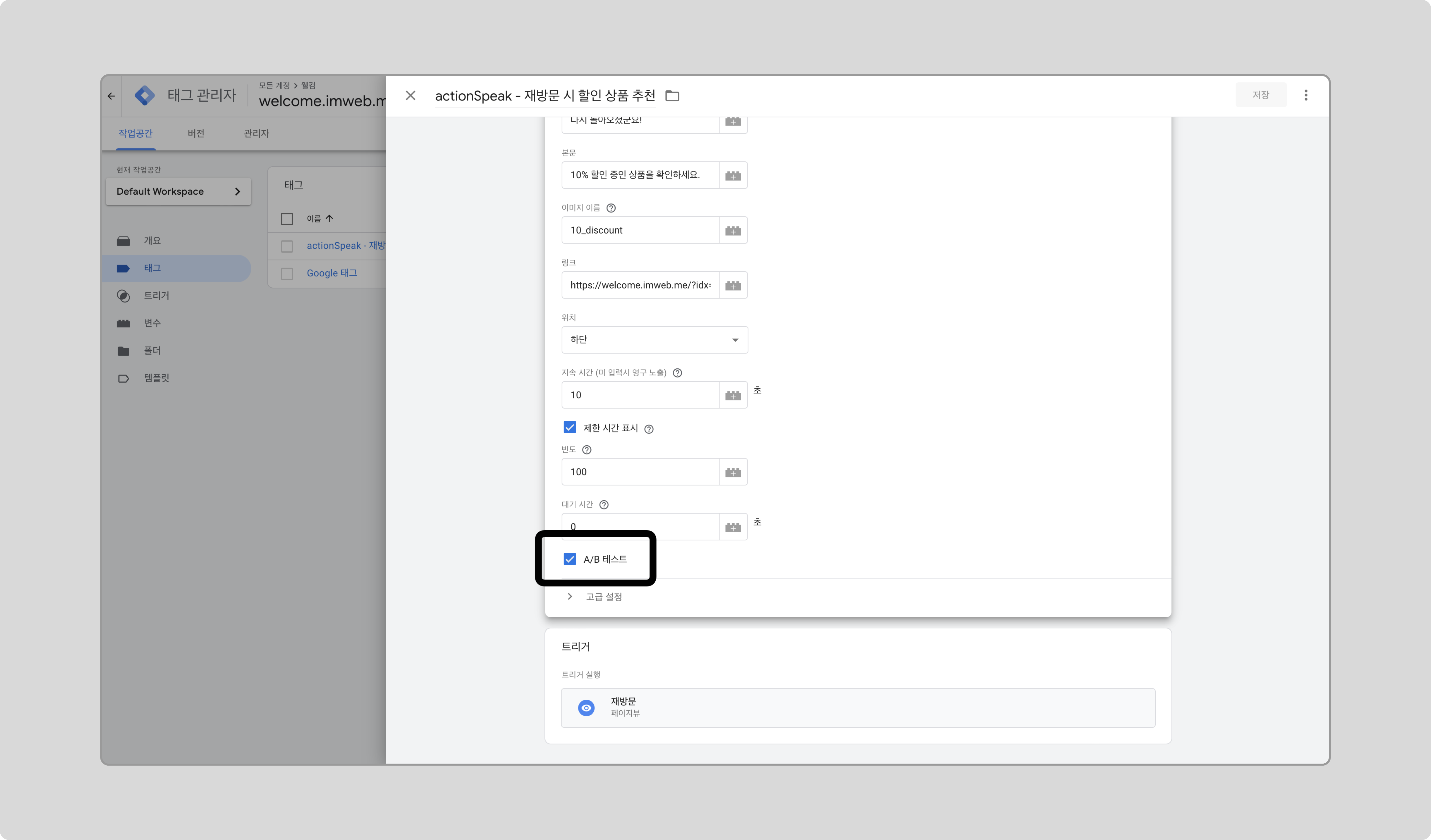
-
‘미리보기’를 클릭합니다.
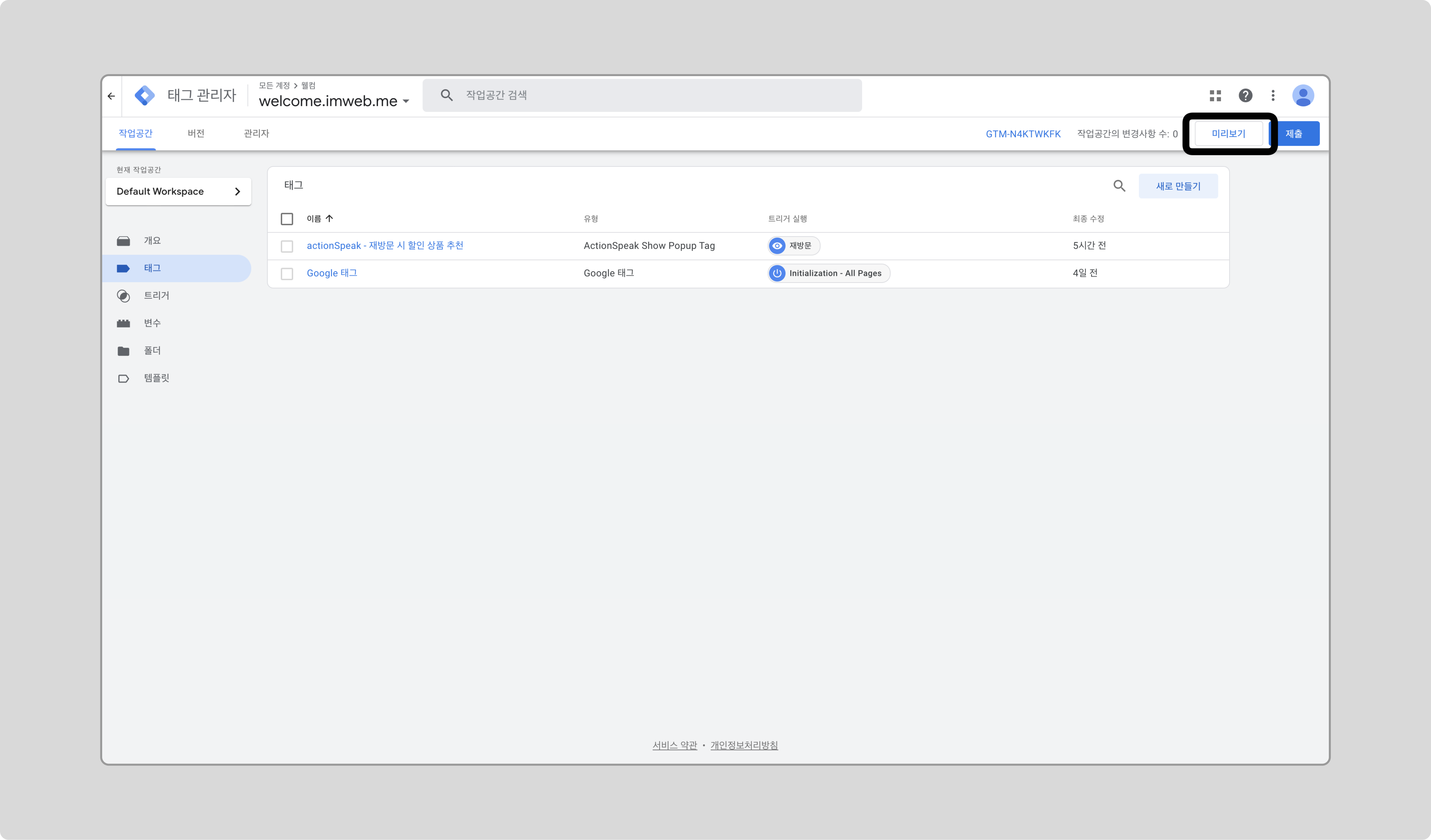
-
개발자 도구를 열어 bucket이 test로 설정되어 있으면 팝업이 노출되는 것을 확인할 수 있습니다.
bucket이 control일 때 팝업 노출을 확인하고 싶다면, bucket이 test가 될 때까지 Local Storage를 비우고 새로고침을 반복해주세요.
사용자 버킷팅 이해하기
actionSpeak는 사용자 식별값과 팝업 식별값을 기반으로 사용자들을 무작위로 test 그룹과 control 그룹에 50% 확률로 배정합니다.
- test 그룹: 팝업이 노출되는 사용자 그룹입니다.
- control 그룹: 팝업이 노출되지 않는 사용자 그룹입니다.
주의사항
동시에 여러 개의 팝업에 대한 A/B 테스트는 피하는 것이 좋습니다. 여러 테스트가 겹치면 결과가 왜곡될 수 있으므로, 한 번에 하나의 테스트를 진행하여 신뢰도 높은 결과를 얻는 것이 좋습니다.
퍼널 데이터 수집: 사용자의 행동 정보 수집하기
A/B 테스트를 더 정밀하게 분석하기 위해서는 단순히 구매 여부뿐만 아니라 다양한 퍼널 데이터를 함께 수집하는 것이 중요합니다. 예를 들어, 팝업이 얼마나 자주 노출되었는지, 사용자가 팝업을 클릭했는지 등을 수집하면 사용자 행동을 더 깊이 분석할 수 있습니다.
이번 예시에서는 팝업 노출, 팝업 클릭, 상품 구매에 대한 데이터를 수집하겠지만, 이 외에도 상품 노출, 상품 클릭 등 퍼널 데이터를 추가하면 테스트 결과를 더욱 정밀하게 분석할 수 있습니다.
팝업 노출 데이터 수집
actionSpeak에서는 팝업이 노출될 때 dataLayer로 팝업 및 사용자 정보를 전달합니다. 이를 활용해 트리거와 변수를 설정해 데이터를 수집할 수 있습니다.
팝업 노출 시 전달하는 dataLayer 객체는 다음과 같습니다:
window.dataLayer.push({
event: "actionSpeak_impression",
asPopupId: popupId,
asPopupTitle: popupTitle,
asPopupType: popupType,
asBucket: bucket,
asTimestamp: new Date().toISOString(),
asVisitorId: visitorId,
});트리거 설정
-
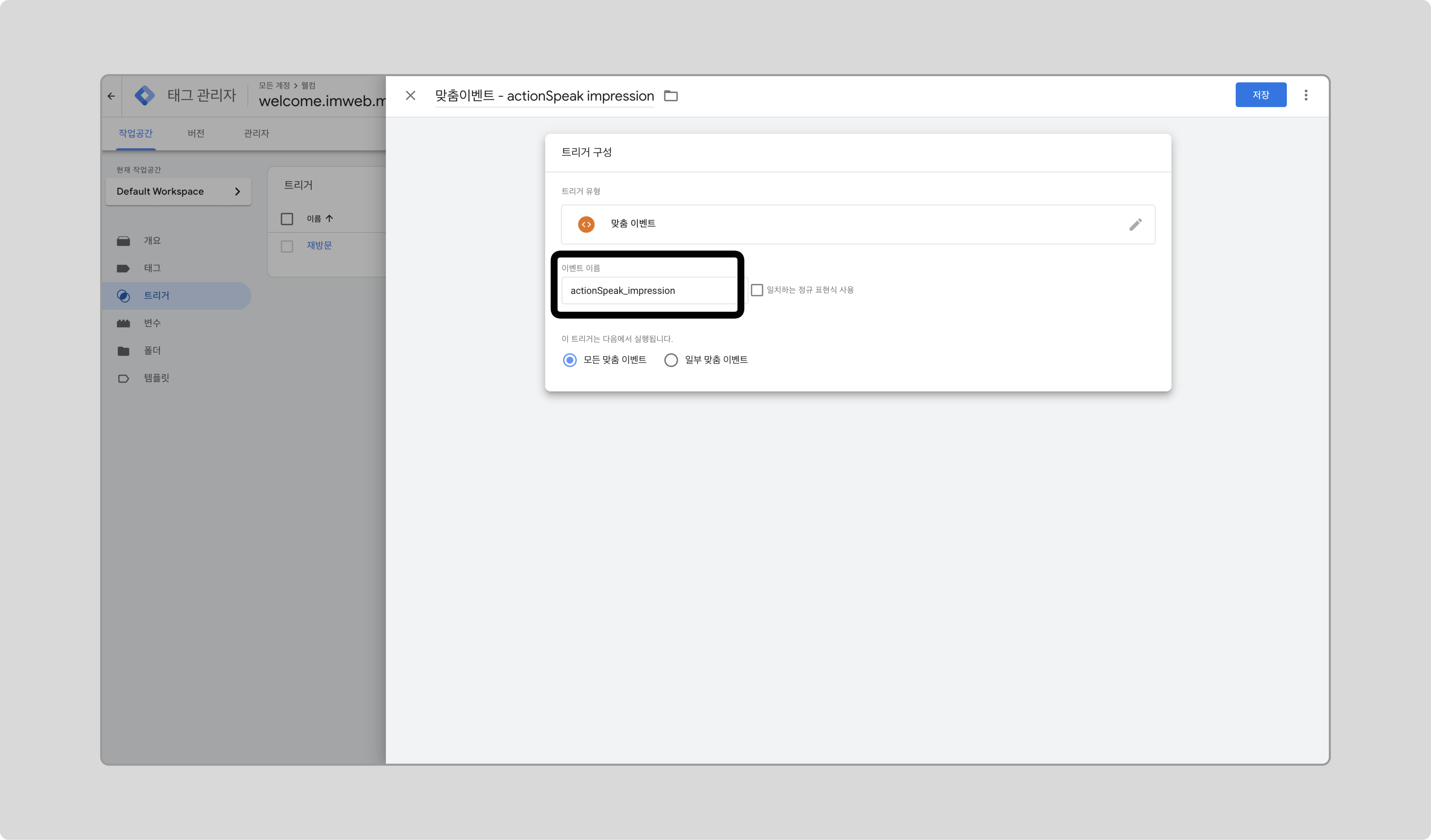
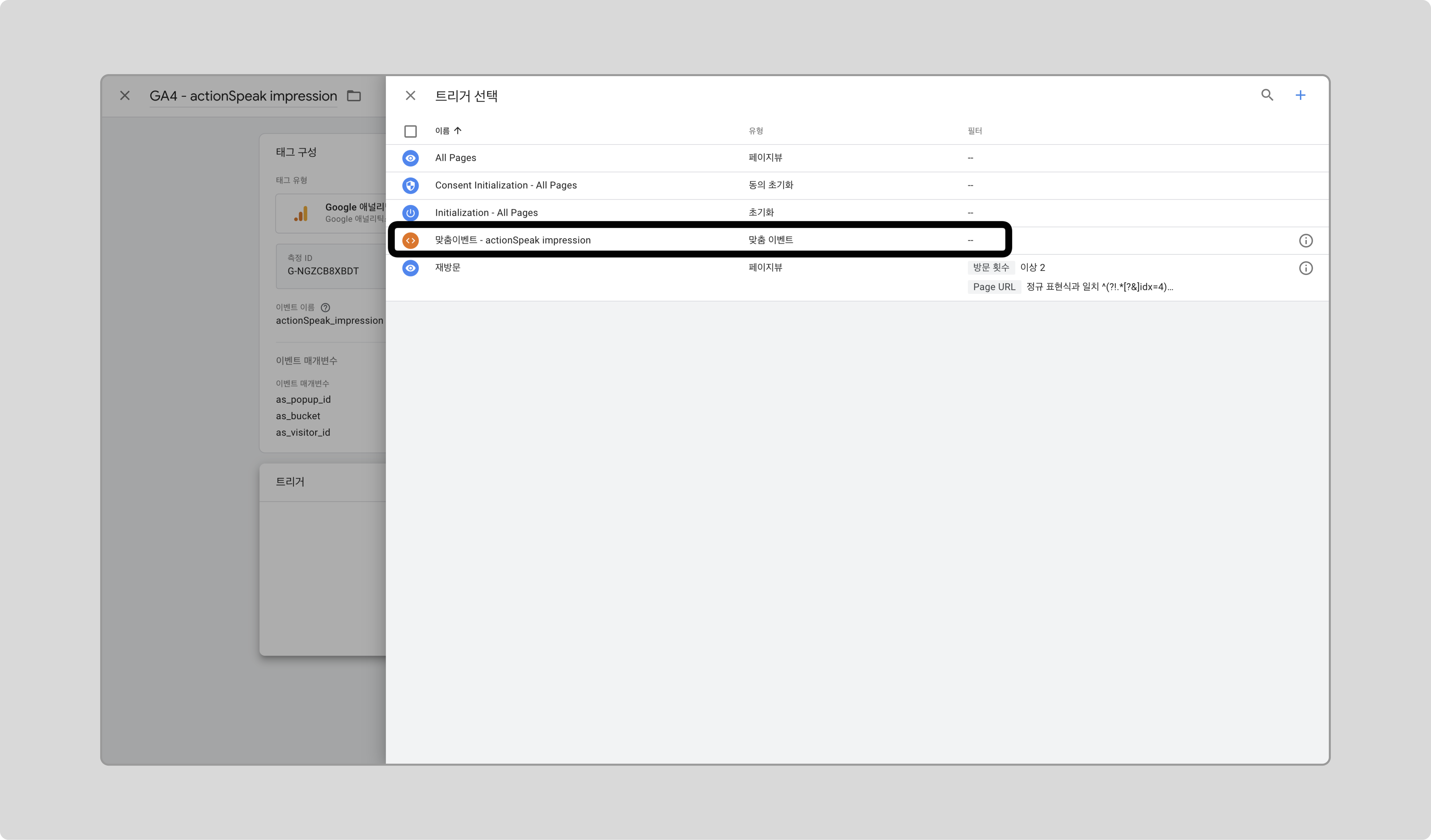
GTM에서 새 트리거를 만들고, 트리거 유형으로 ‘맞춤 이벤트’를 선택합니다.

-
이벤트 이름에 actionSpeak_impression을 입력하고 저장합니다.
변수 설정
-
GTM에서 새 변수를 만들고, 변수 유형으로 ‘데이터 영역 변수’를 선택합니다.
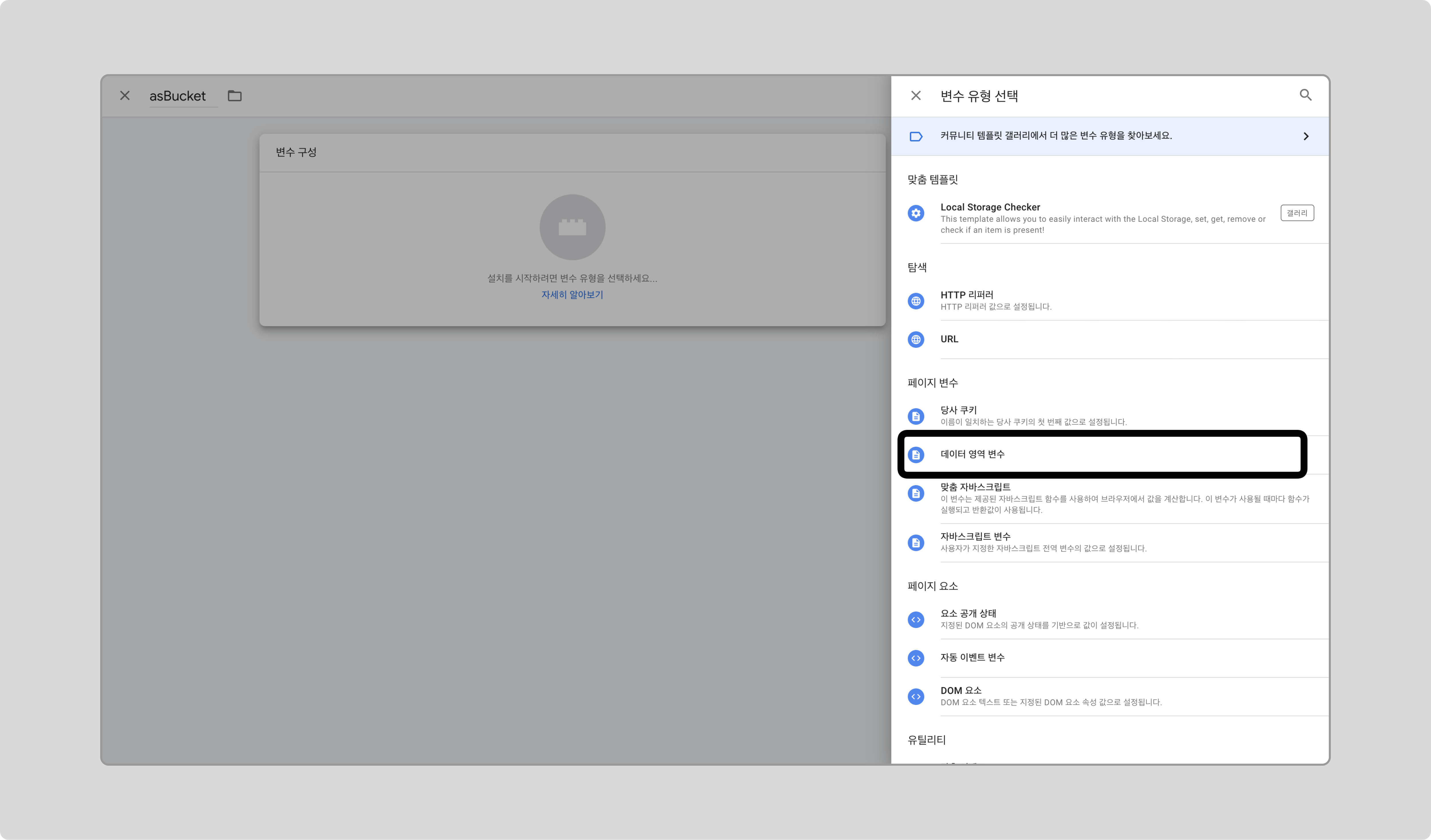
-
데이터 영역 변수 이름에 asBucket을 입력하고 저장합니다.
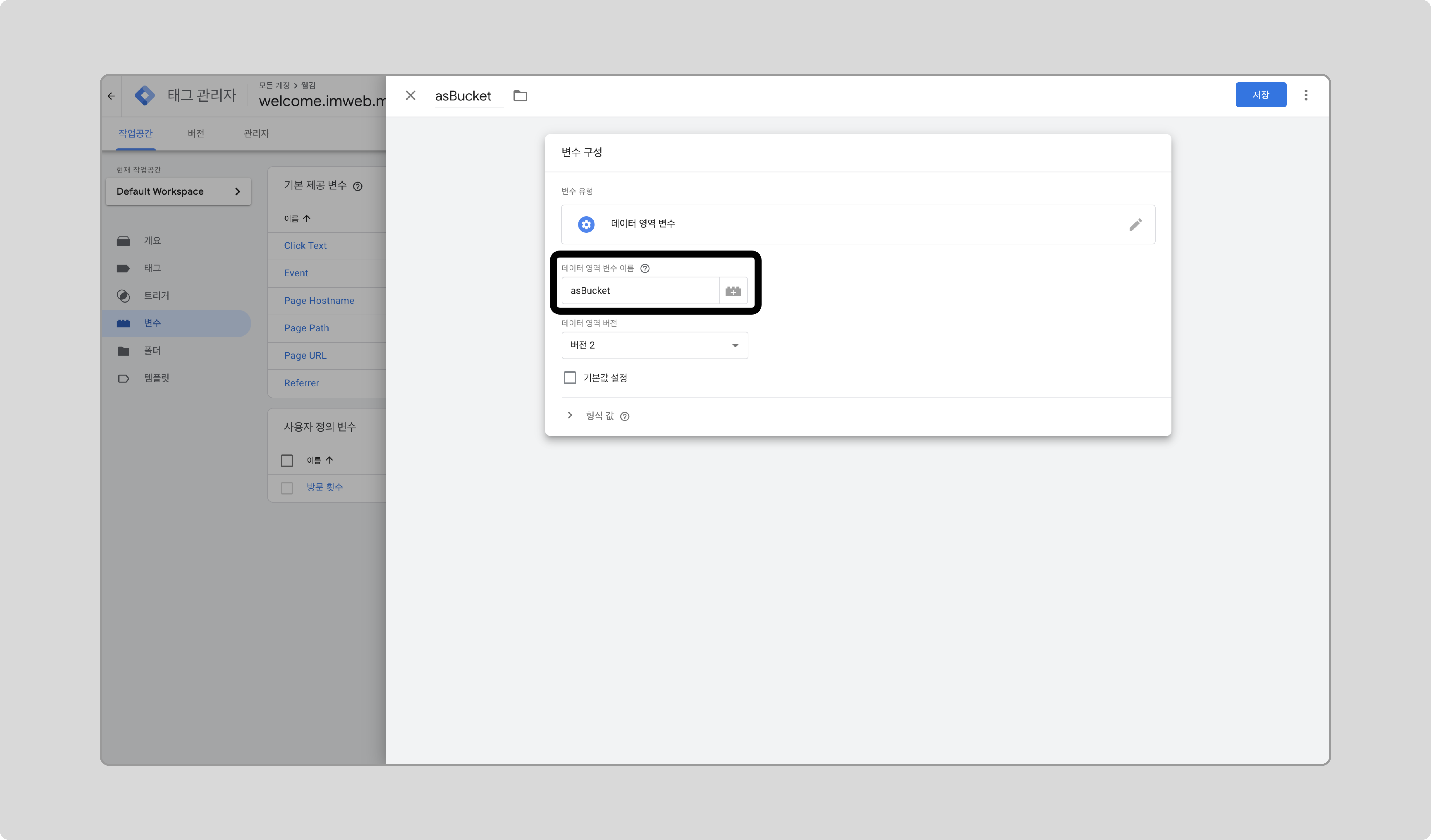
-
같은 방식으로 asPopupId와 asVisitorId 변수도 추가합니다.
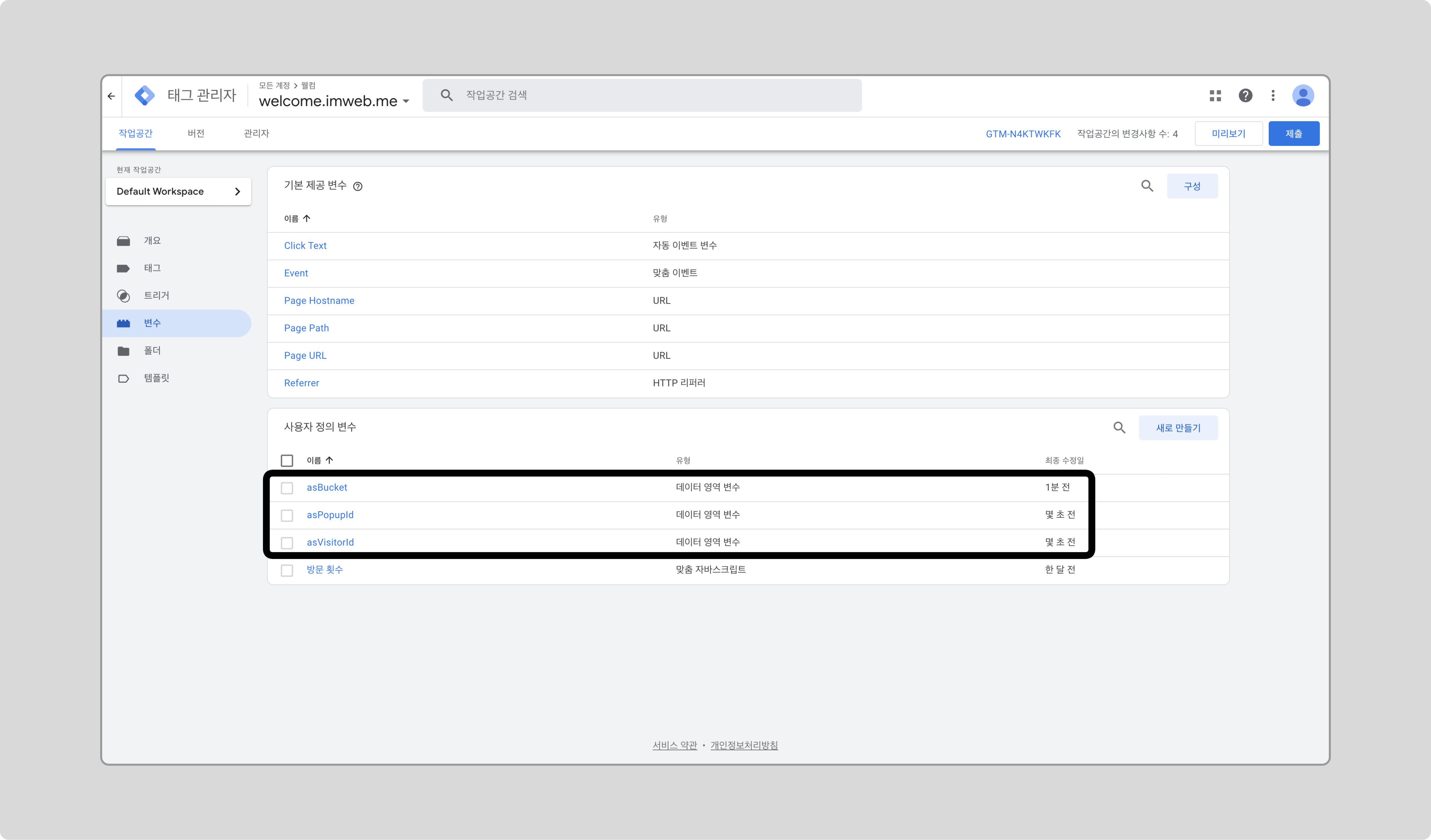
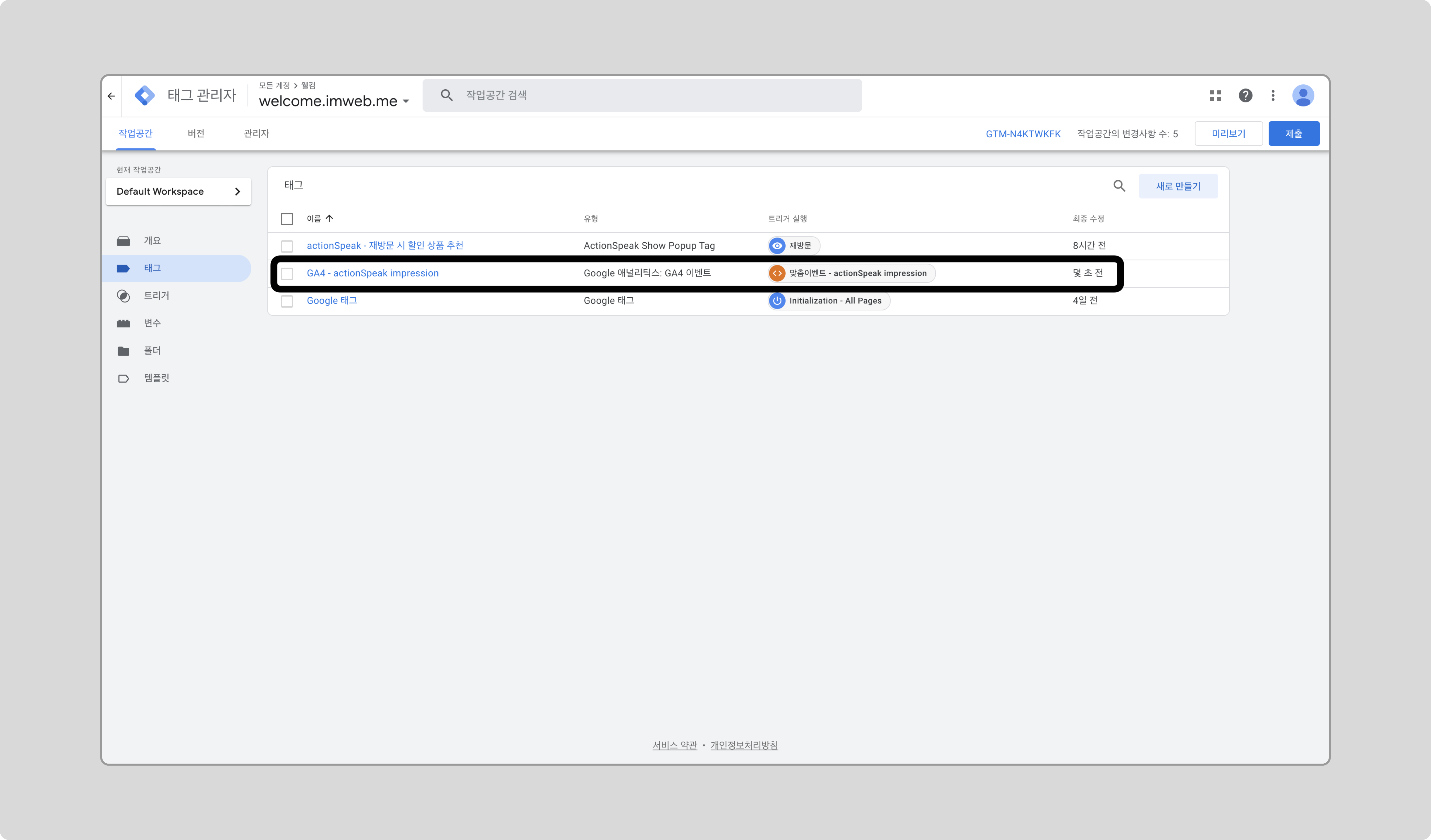
태그 설정
-
태그를 새로 만들고, 태그 유형으로 [Google 애널리틱스] > [GA4 이벤트]를 선택합니다.
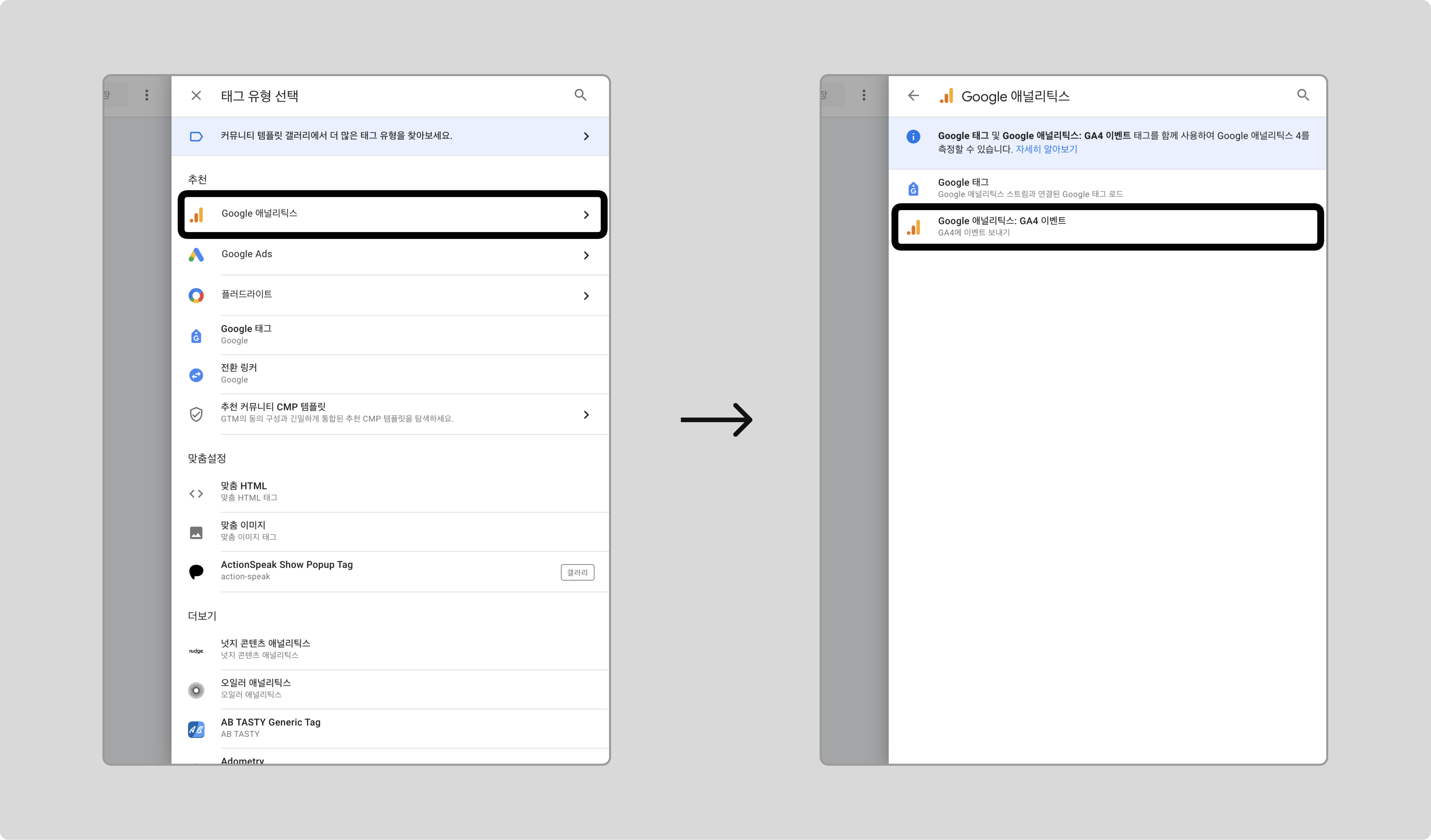
-
측정 ID에 연동된 GA4의 태그 ID를 입력합니다.
GTM과 GA4를 연동하지 않았다면 GTM과 GA4 연동하기를 참고해주세요. 이미 연동한 경우, 태그 ID는 GA4를 연동할 때 사용한 태그에서 확인할 수 있습니다.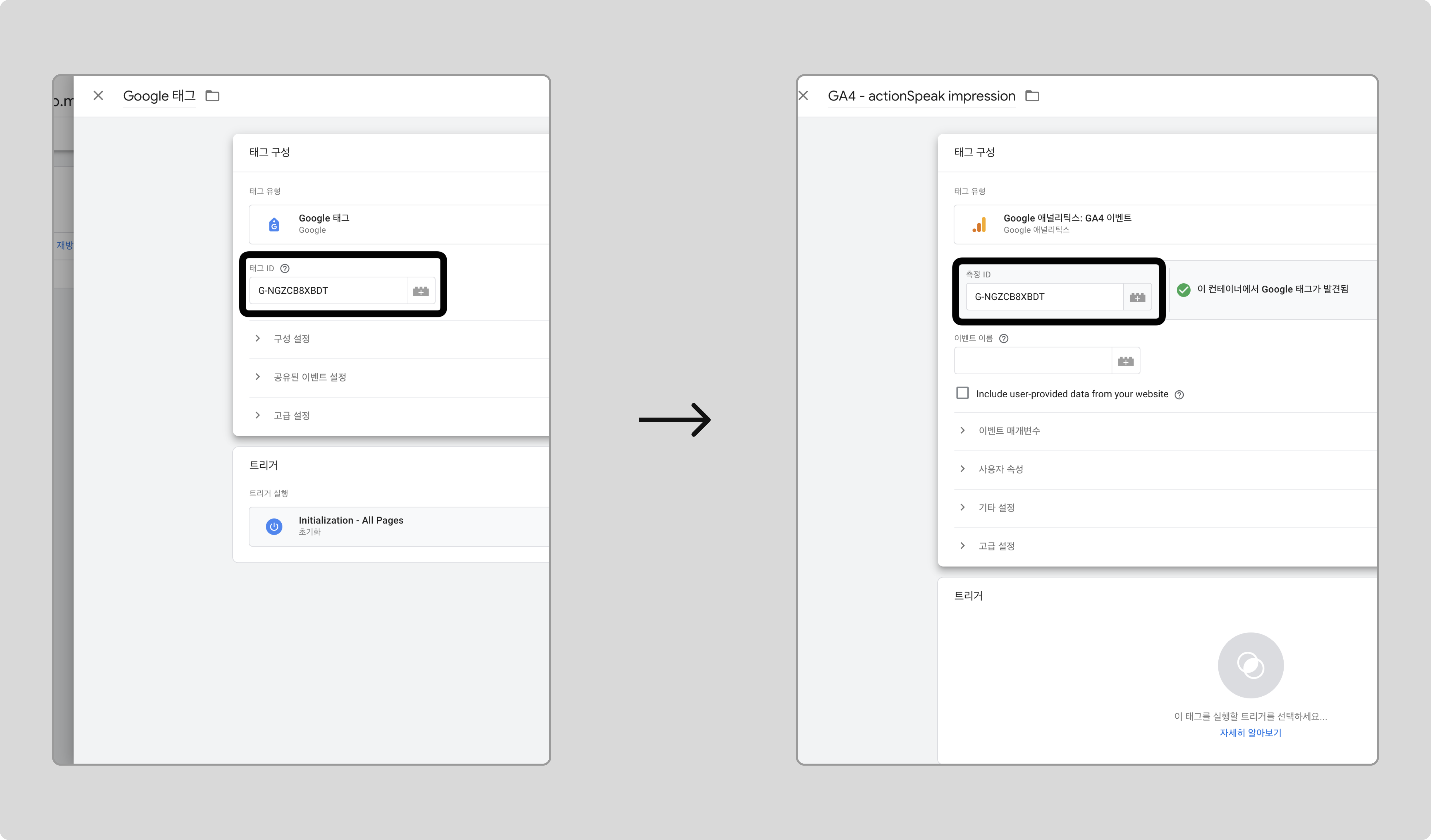
-
이벤트 이름을 입력합니다.
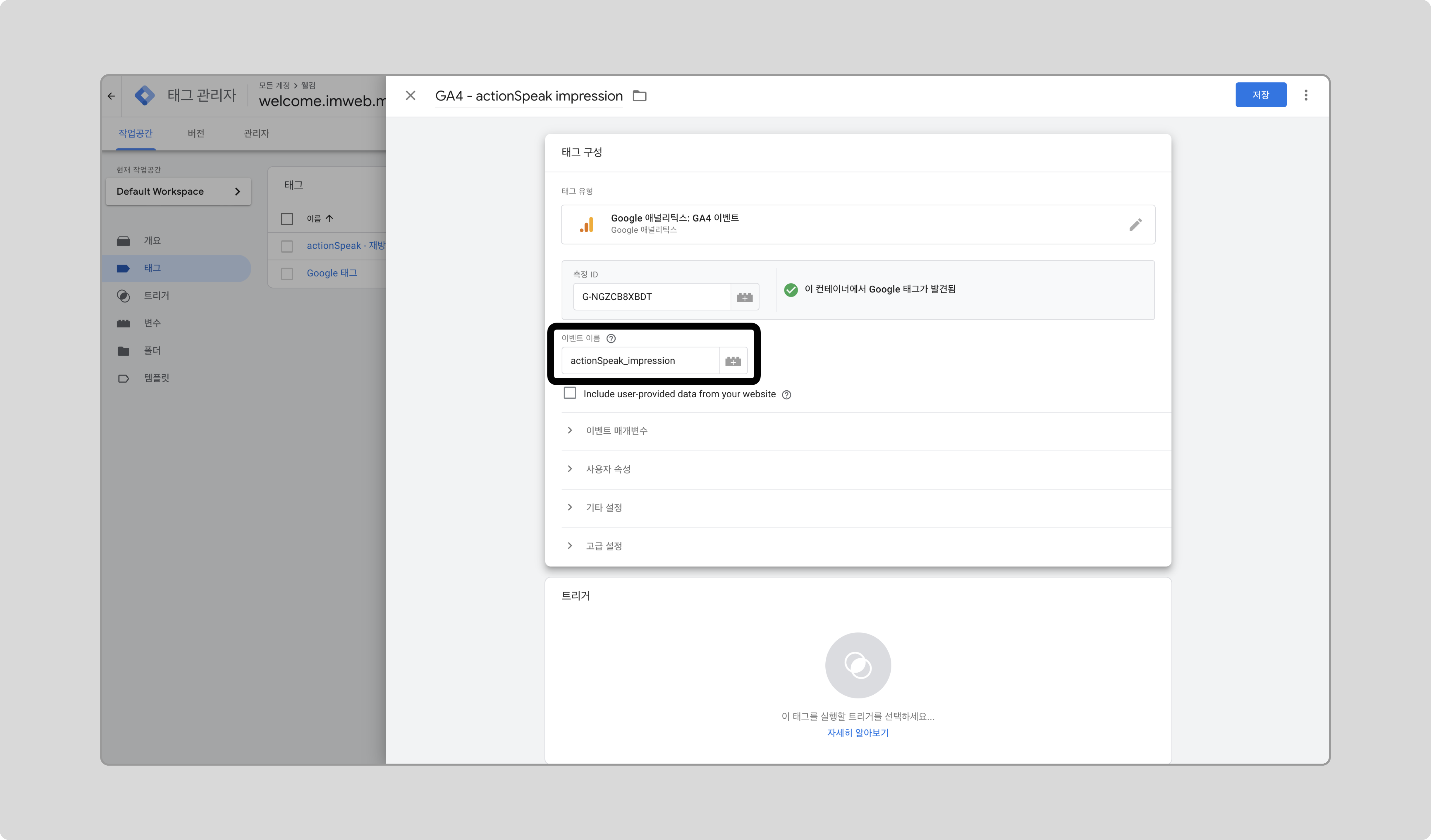
-
이벤트 매개변수로 앞서 만든 변수를 추가합니다.
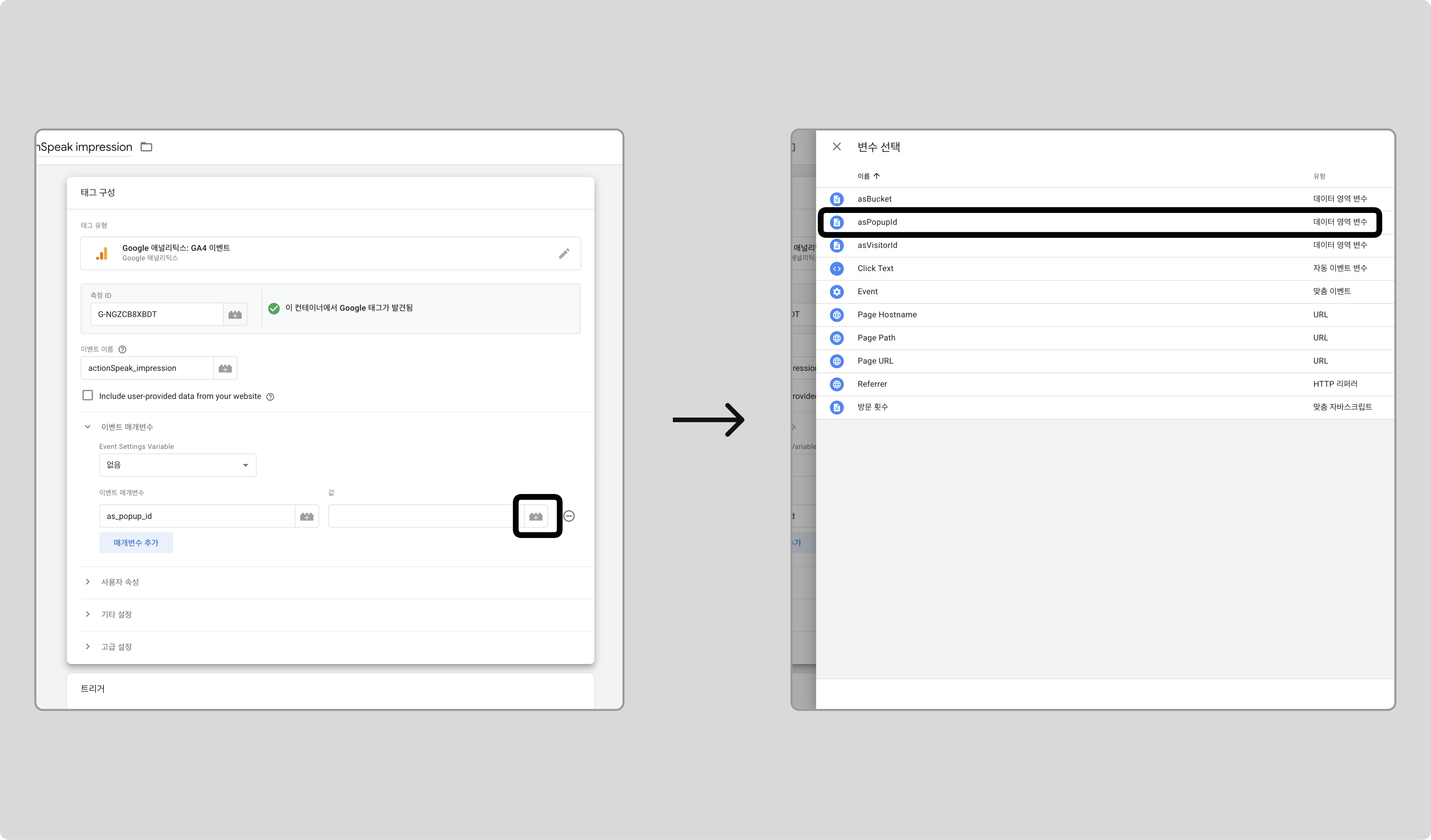
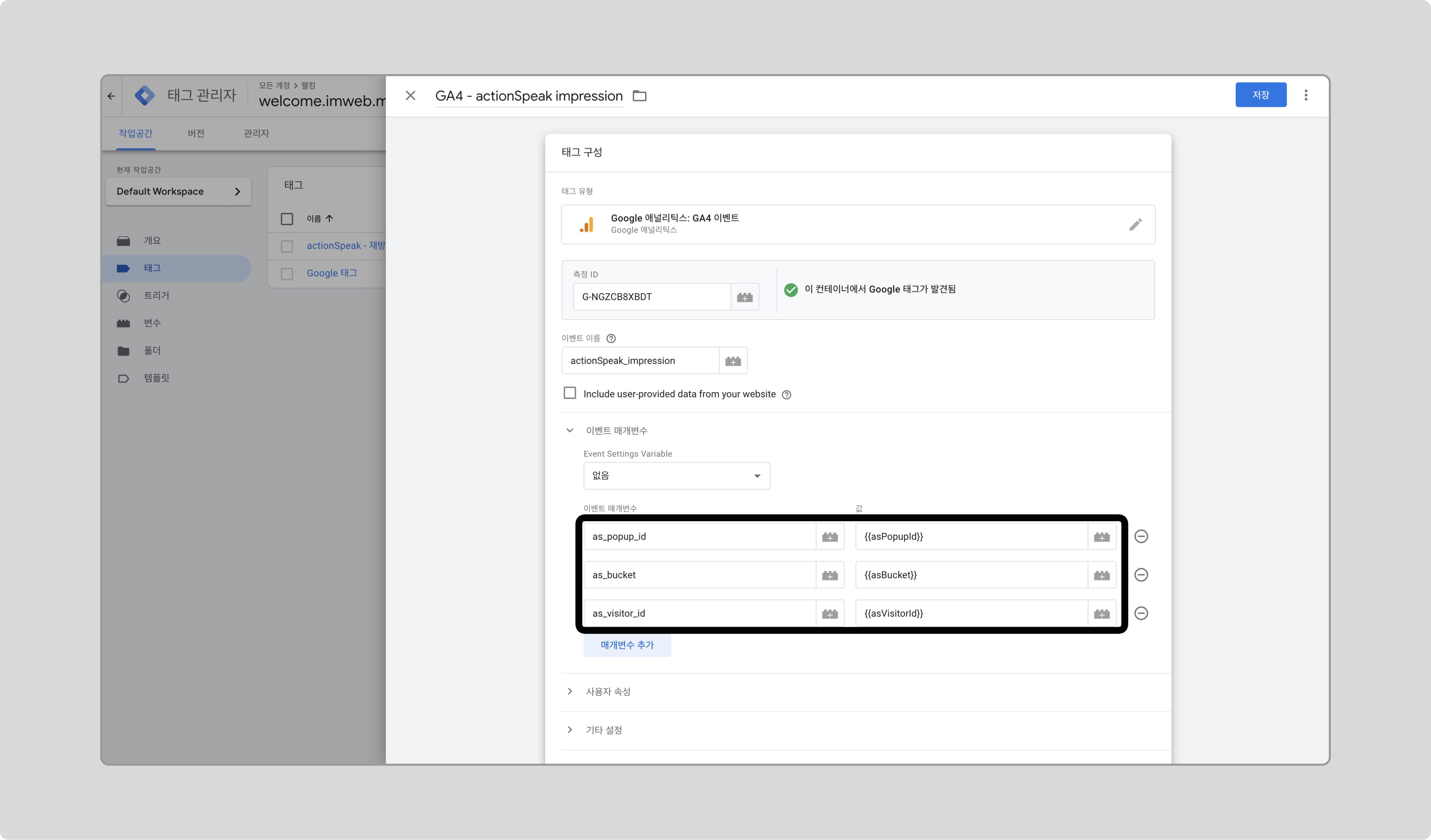
-
트리거로 앞서 추가한 트리거를 선택하고 저장합니다.
팝업 클릭 데이터 수집
팝업 클릭도 팝업 노출과 마찬가지로 dataLayer로 해당 팝업과 사용자의 정보를 전달합니다.
dataLayer 객체는 다음과 같습니다:
window.dataLayer.push({
event: "actionSpeak_click",
asPopupId: popupId,
asPopupTitle: popupTitle,
asPopupType: popupType,
asBucket: bucket,
asTimestamp: new Date().toISOString(),
asVisitorId: visitorId,
});트리거 설정
-
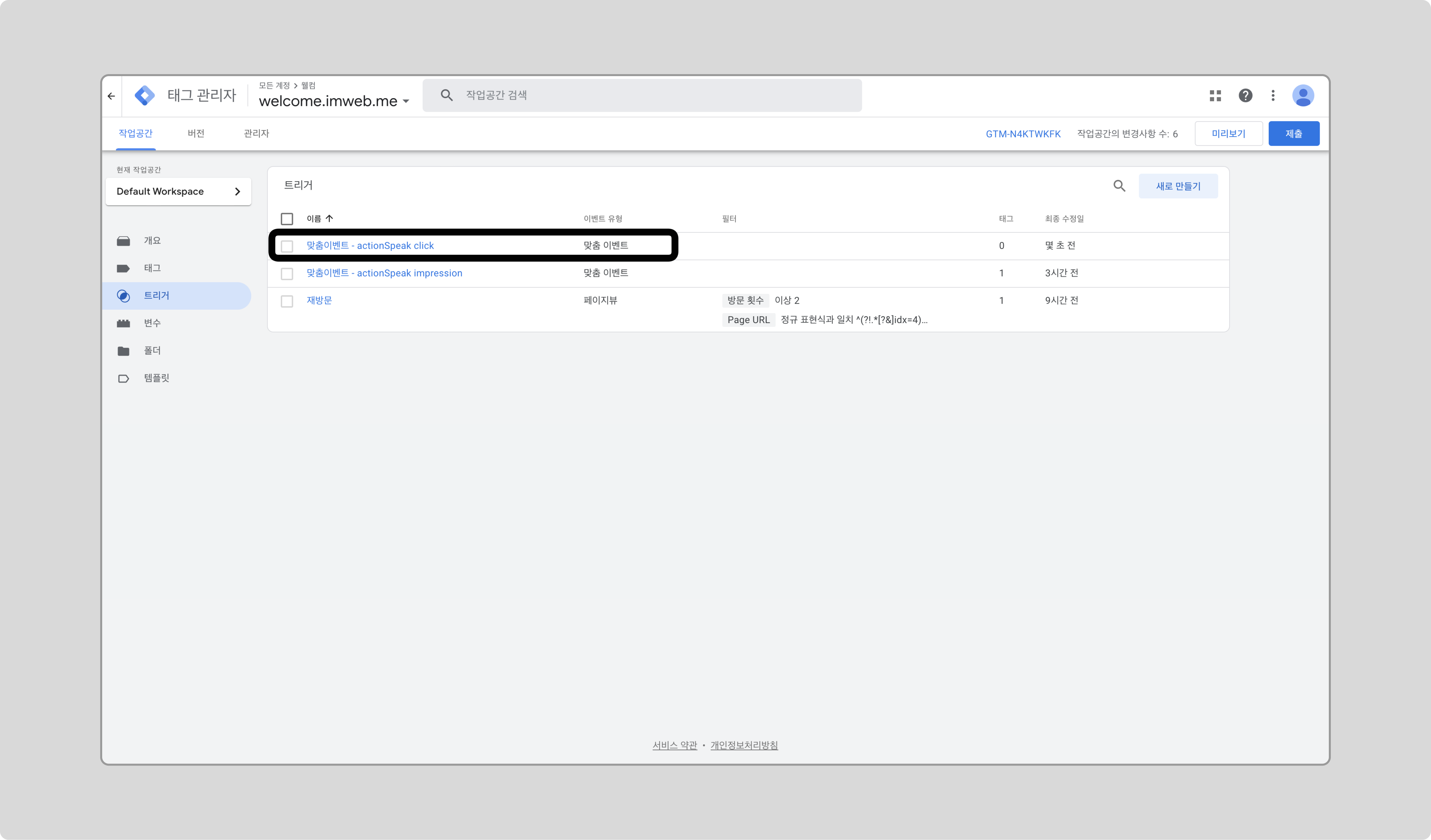
actionSpeak_click을 이벤트 이름으로 하는 맞춤 이벤트 트리거를 생성합니다.
태그 설정
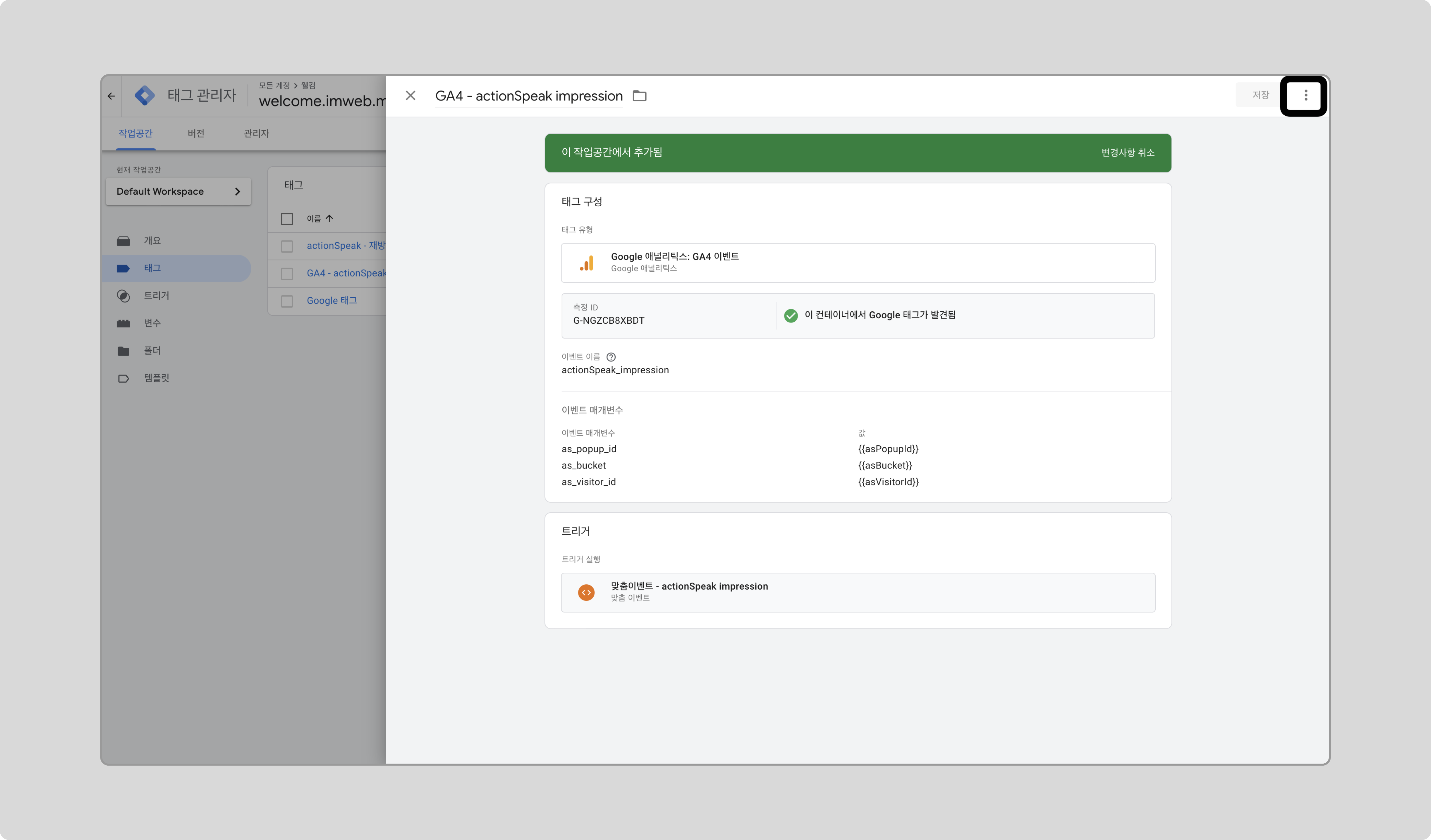
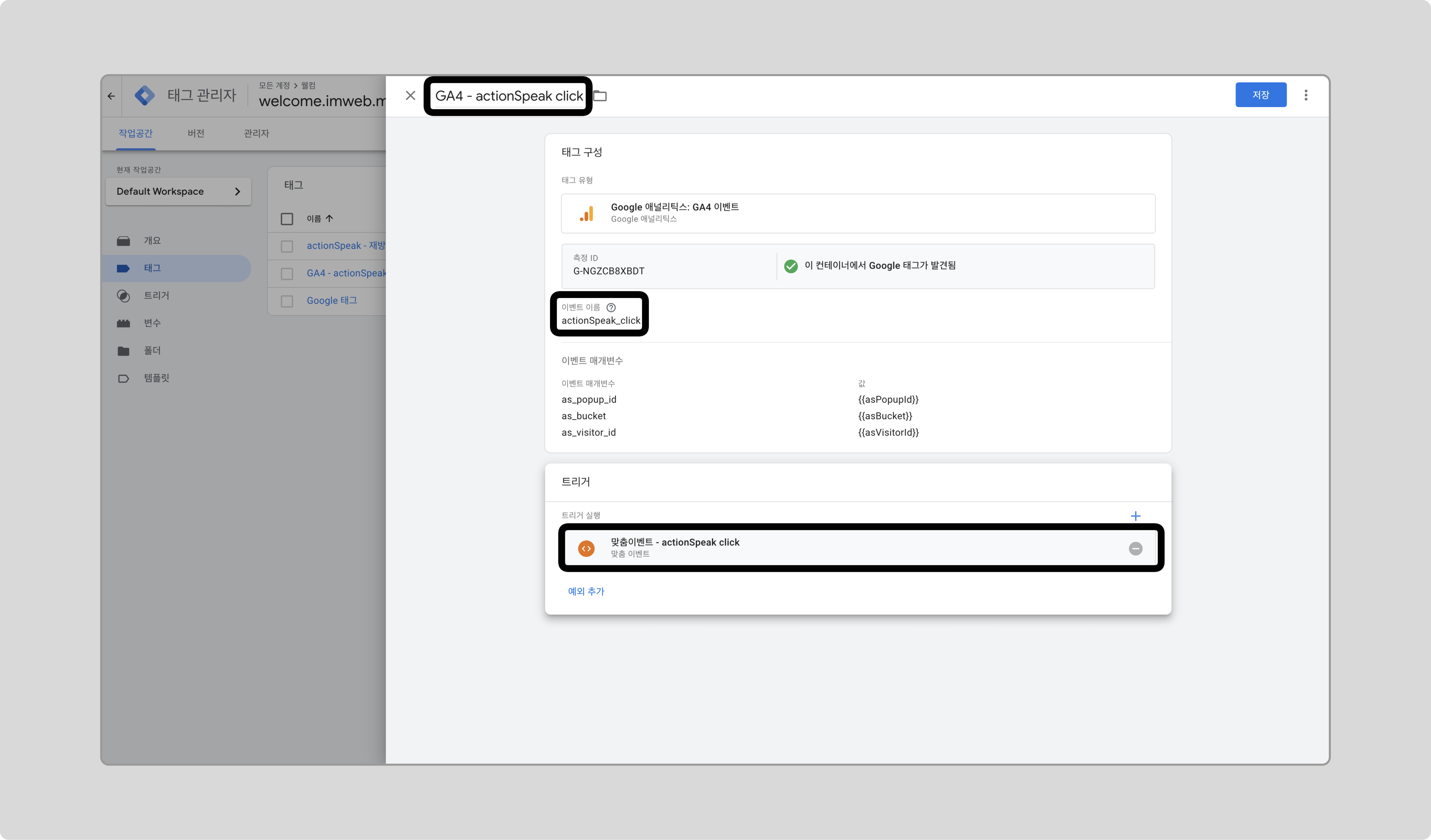
이전에 만든 태그와 동일한 변수 구성이므로 이전 태그를 복사해서 사용합니다.
-
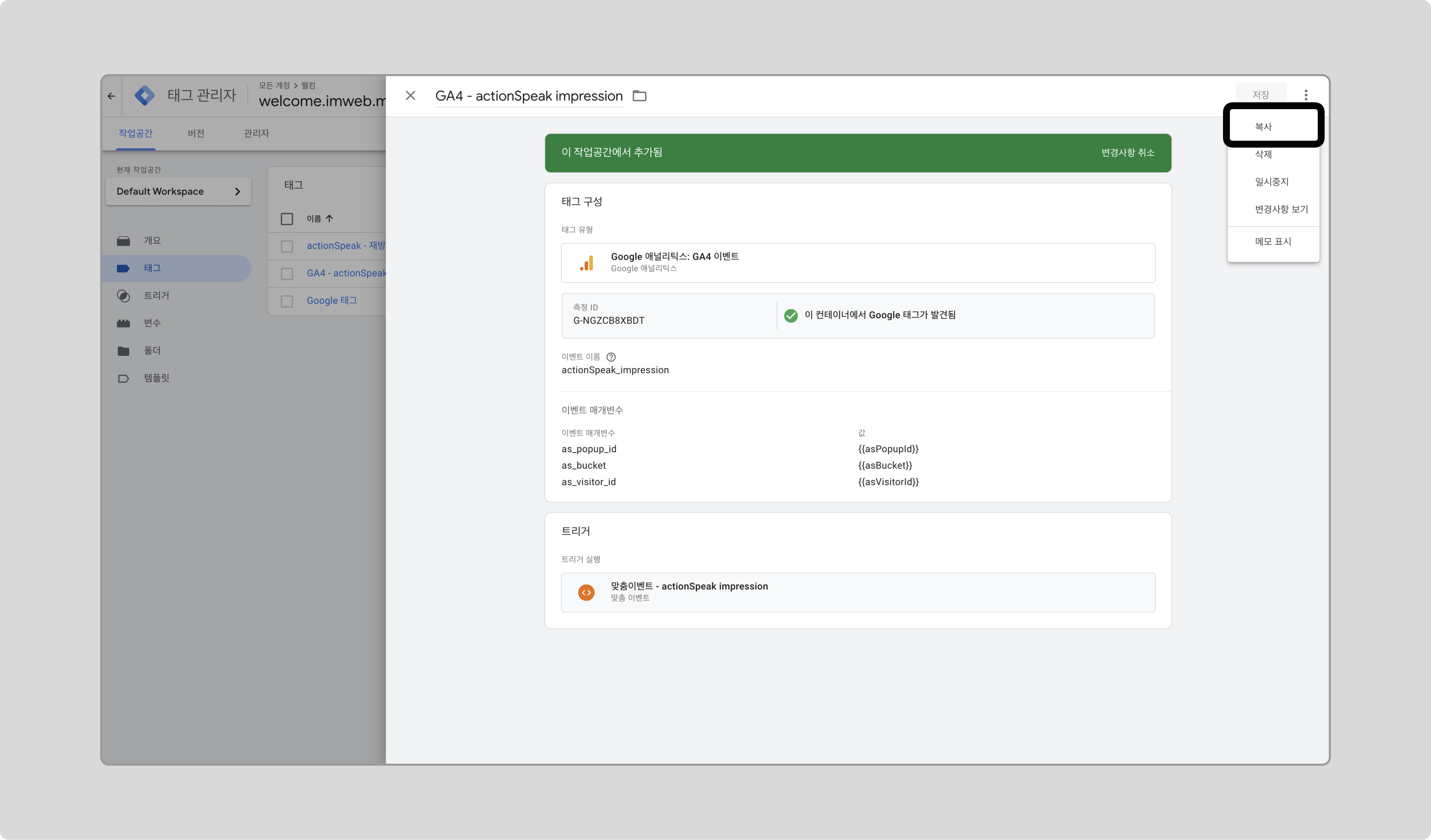
이전에 만든 태그로 선택하고, 우측 상단 아이콘을 클릭해서 ‘복사’를 클릭합니다.
-
태그명, 이벤트 이름, 트리거를 수정한 후 저장합니다.
상품 구매 데이터 수집
상품 구매는 actionSpeak 팝업 이벤트와 달리 dataLayer로 전달받는 정보가 없기 때문에, 직접 구매 시점 정의하고 구매 정보를 수집해야 합니다.
트리거 설정
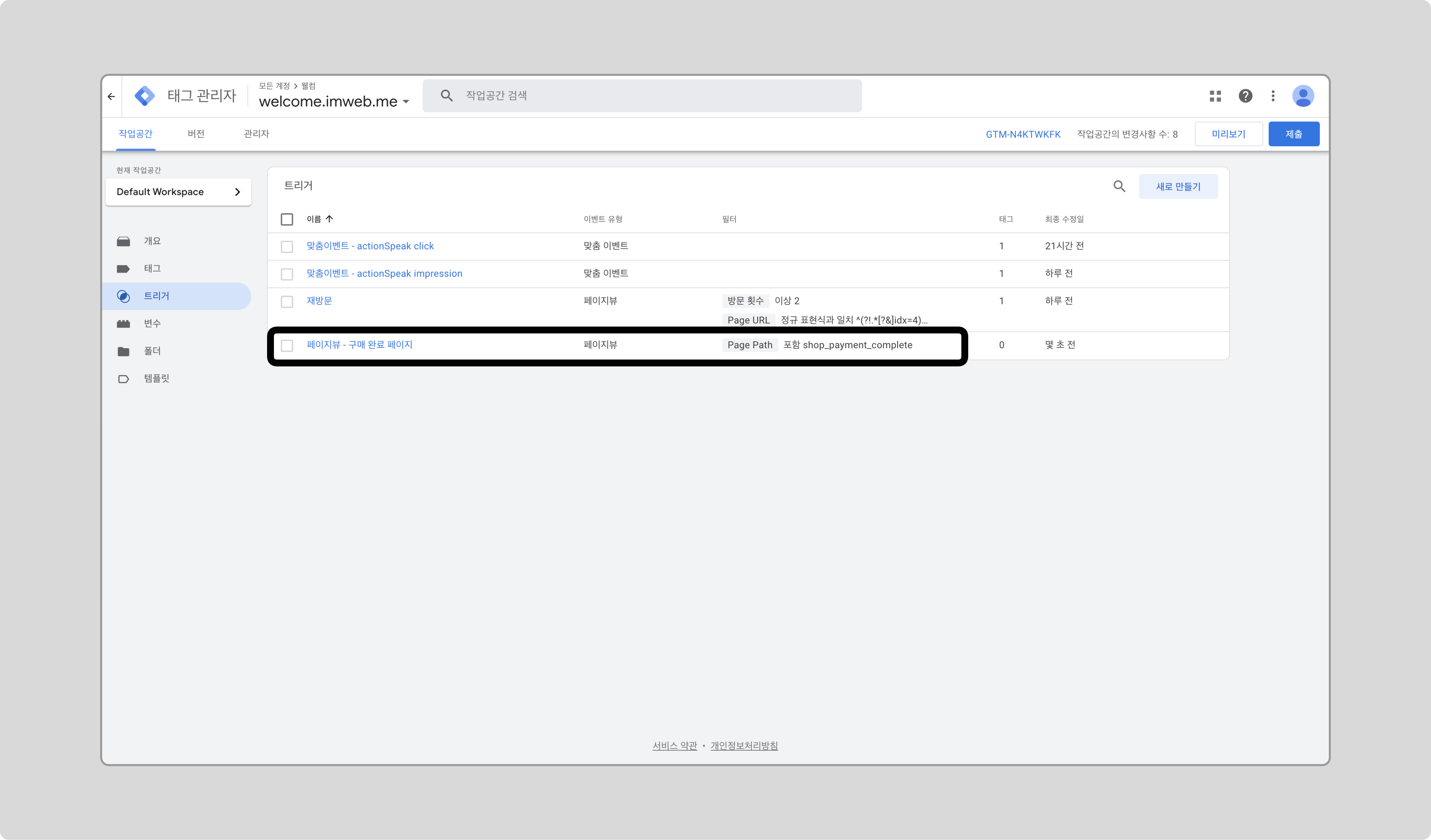
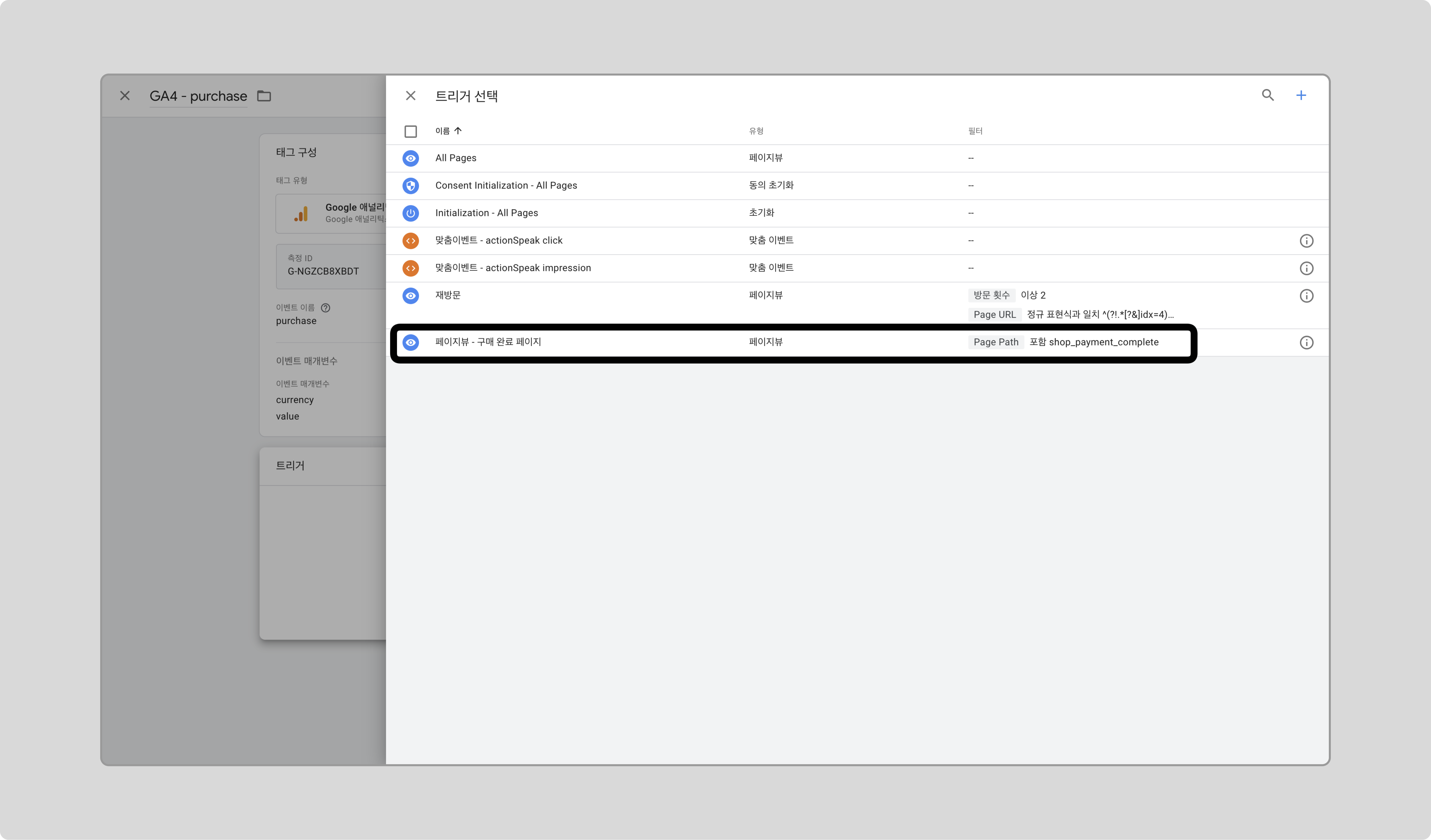
구매 완료 페이지에 도달하는 시점을 트리거로 설정하겠습니다.
-
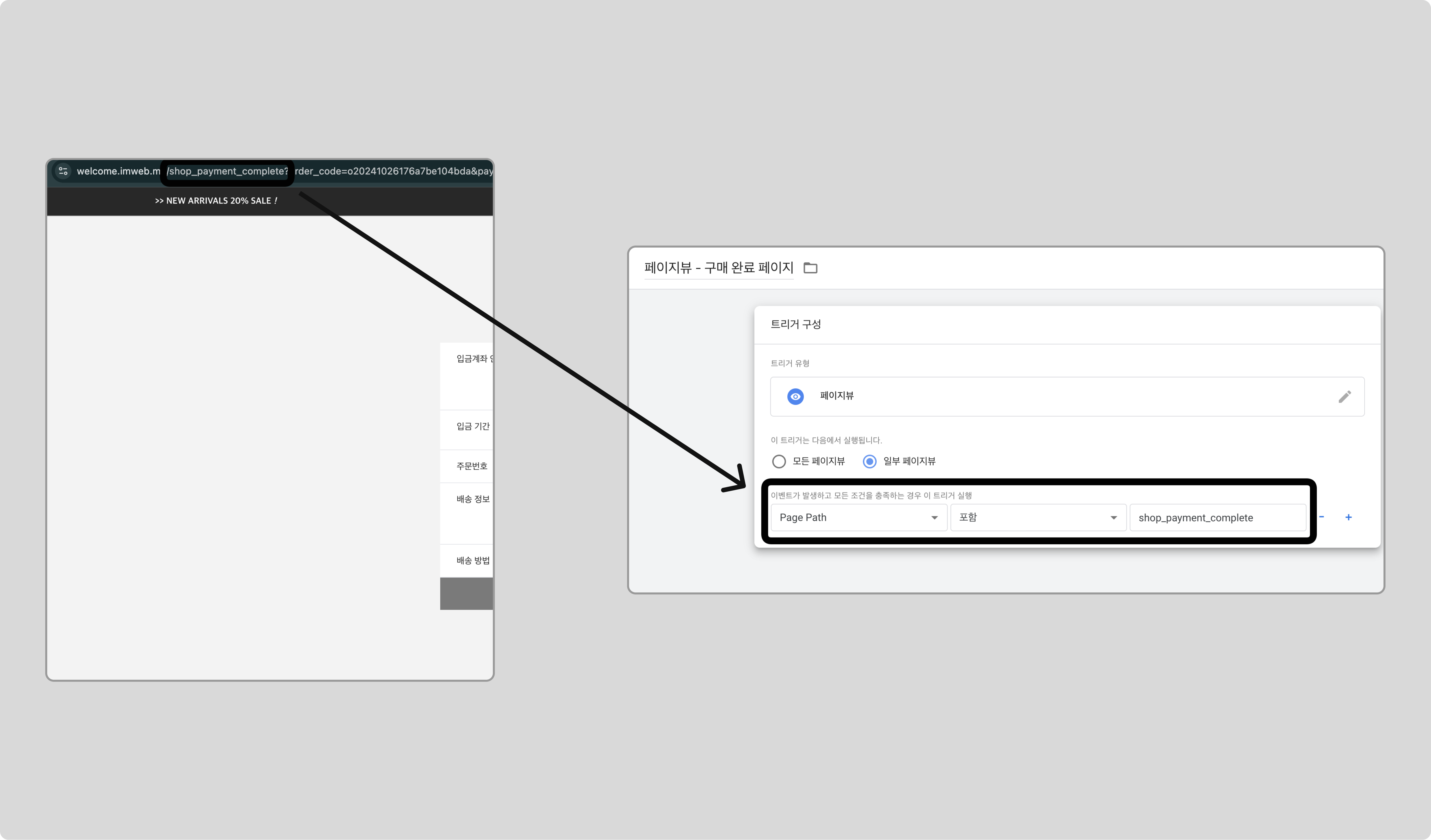
GTM에서 새 트리거를 만들고, 트리거 유형으로 ‘페이지 뷰’를 선택하고, 일부 페이지뷰 조건으로 Page Path 가 구매 페이지의 path를 포함하는 것을 추가하고 저장합니다.
📌
/shop_payment_complete는 구매 완료 페이지의 URL path입니다. 해당 경로는 웹사이트에 따라 다를 수 있으므로 확인 후 변경하세요.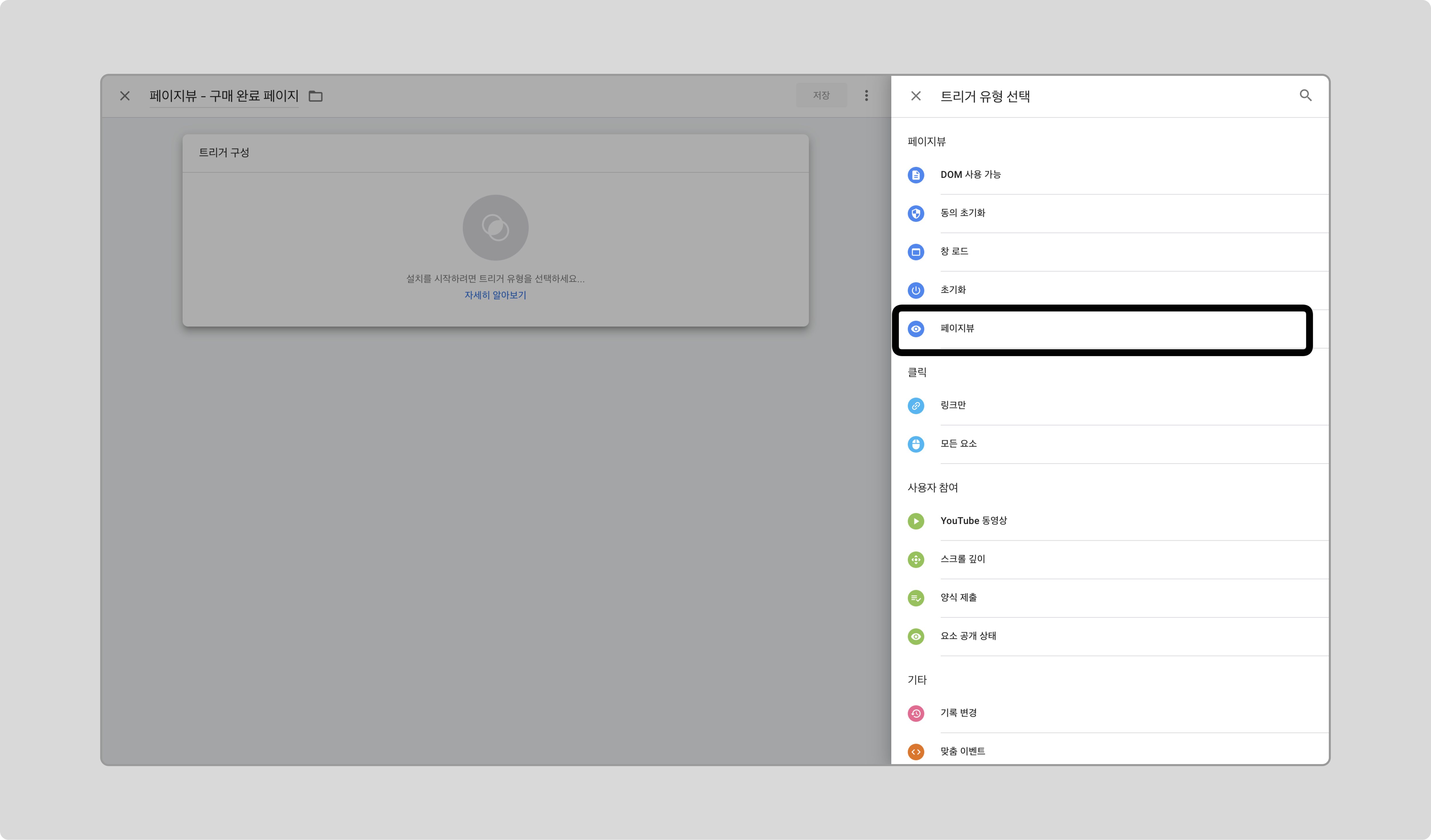
변수 설정
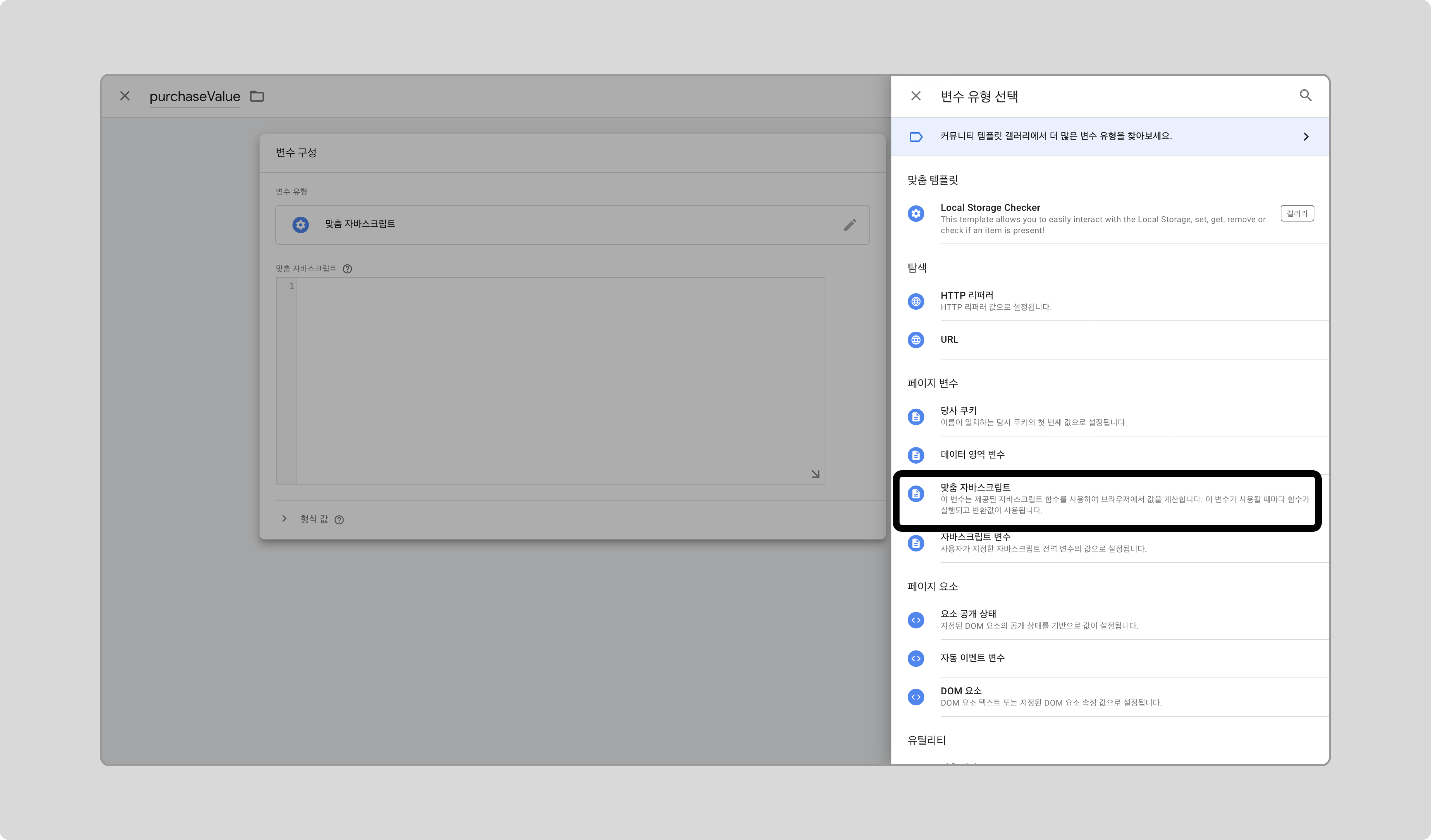
구매 가격 정보를 수집하기 위해 웹사이트 HTML에서 직접 수집합니다.
-
새로운 변수를 만들고, 변수 유형으로 '맞춤 자바스크립트'를 선택합니다.
-
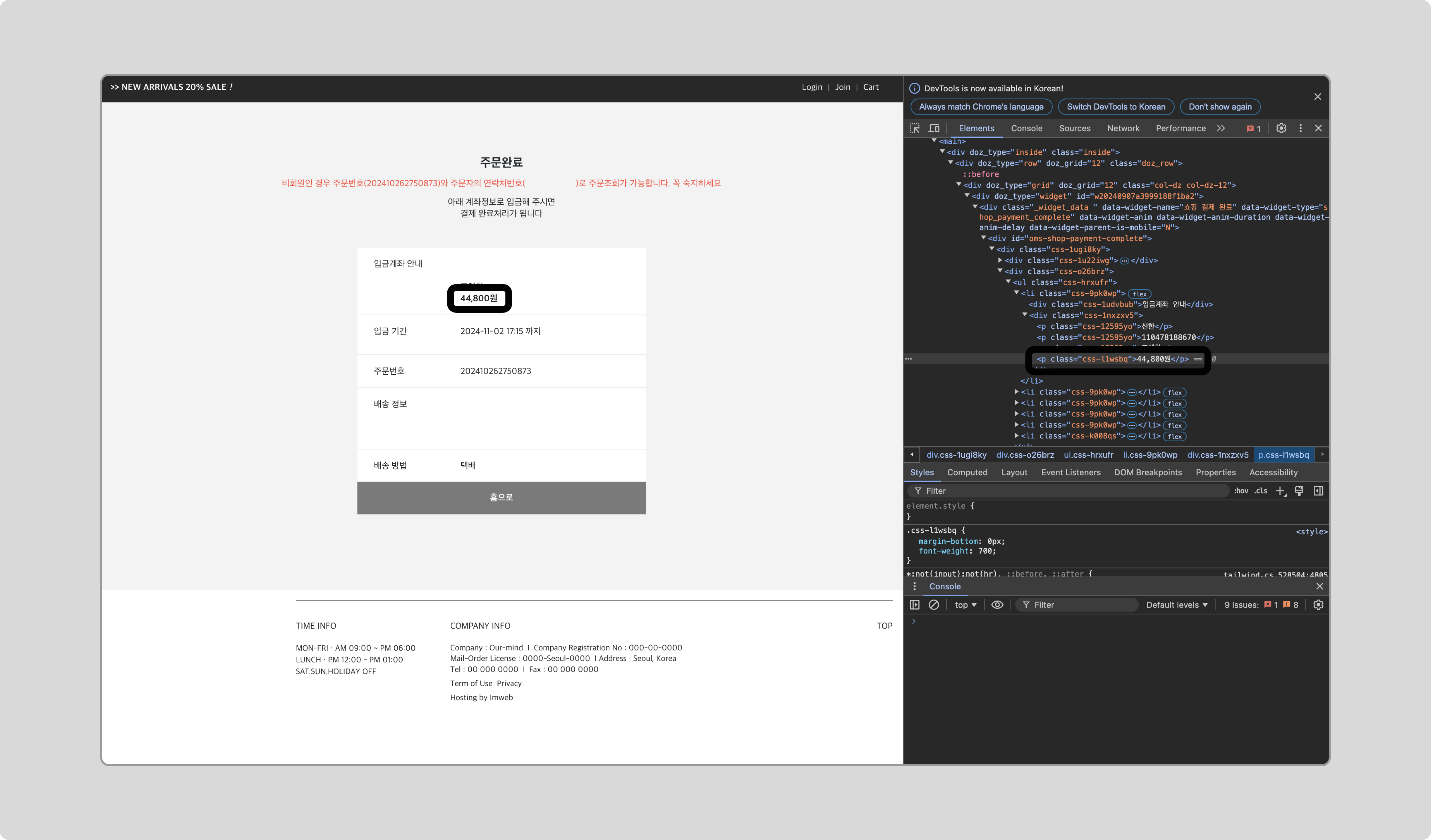
구매 완료 페이지에서 개발자 도구를 열어 가격 정보를 식별할 수 있는 선택자를 확인합니다.
-
확인한 선택자를 이용해 가격 정보를 추출하고 숫자만 남기는 자바스크립트 코드를 작성한 후, 저장합니다.
function () { var purchaseValue = document.querySelector(".css-l1wsbq"); return parseFloat(purchaseValue.replace(/[^0-9]/g, '')); }📌
.css-l1wsbq는 구매 금액을 표시하는 HTML 클래스 이름입니다. 웹사이트마다 다를 수 있으므로, 적절한 선택자를 확인하여 변경하세요.
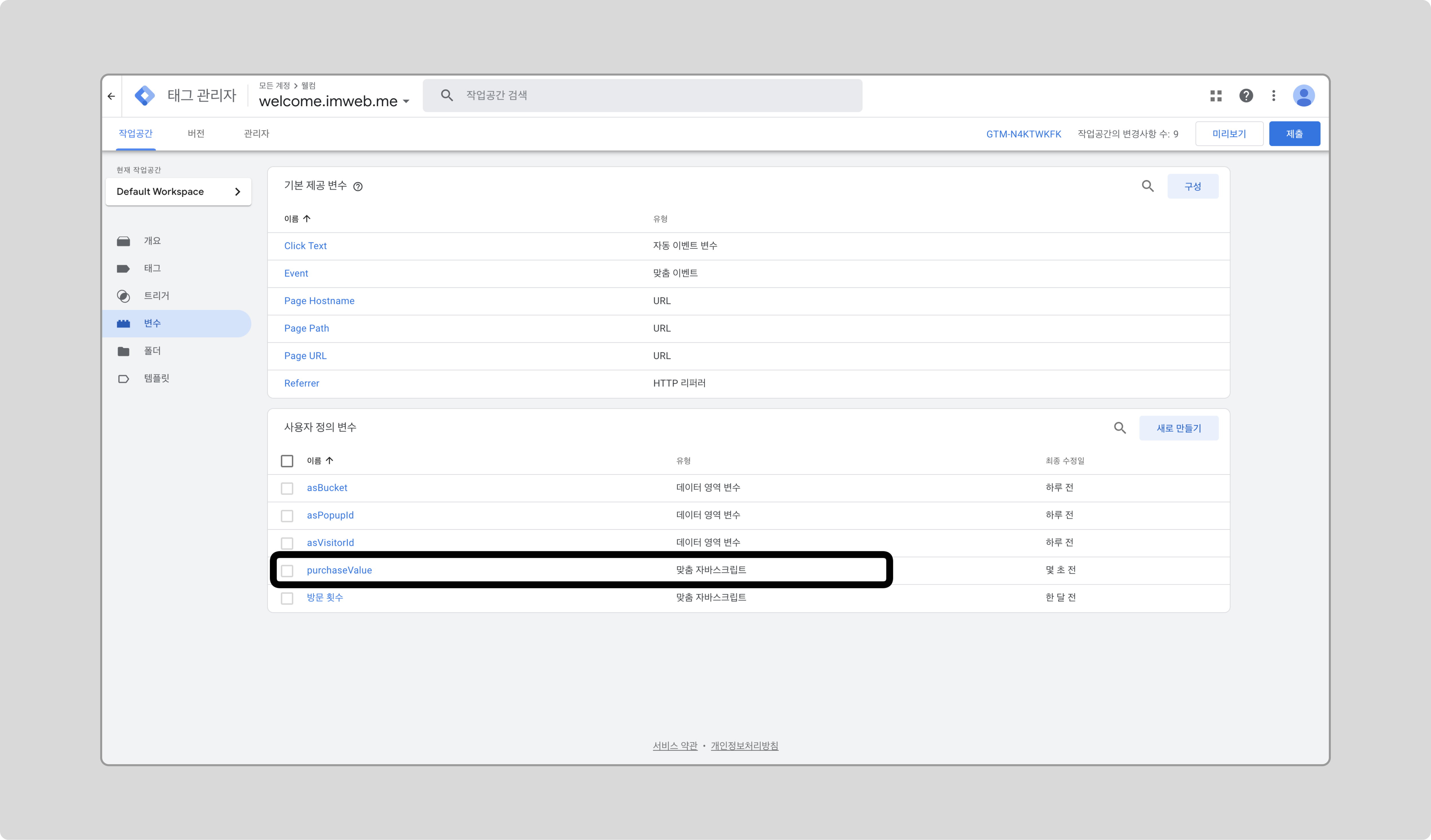
태그 설정
-
새로운 태그를 만들고, 태그 유형으로 [Google 애널리틱스] > [Google 애널리틱스: GA4 이벤트]를 선택합니다.
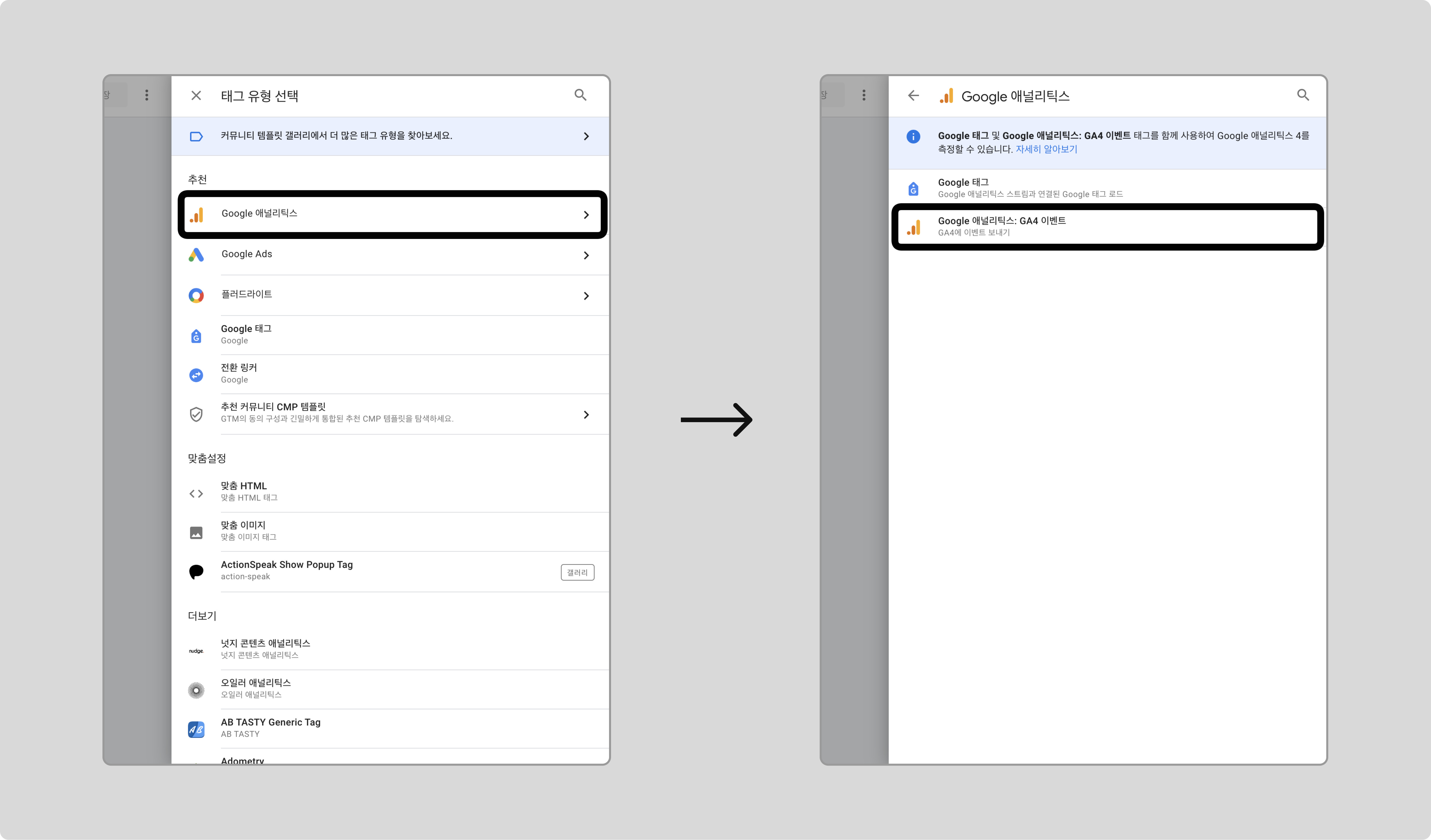
-
측정 ID에 연동된 GA4의 태그 ID를 입력하고, 이벤트 이름을 purchase로 입력합니다.
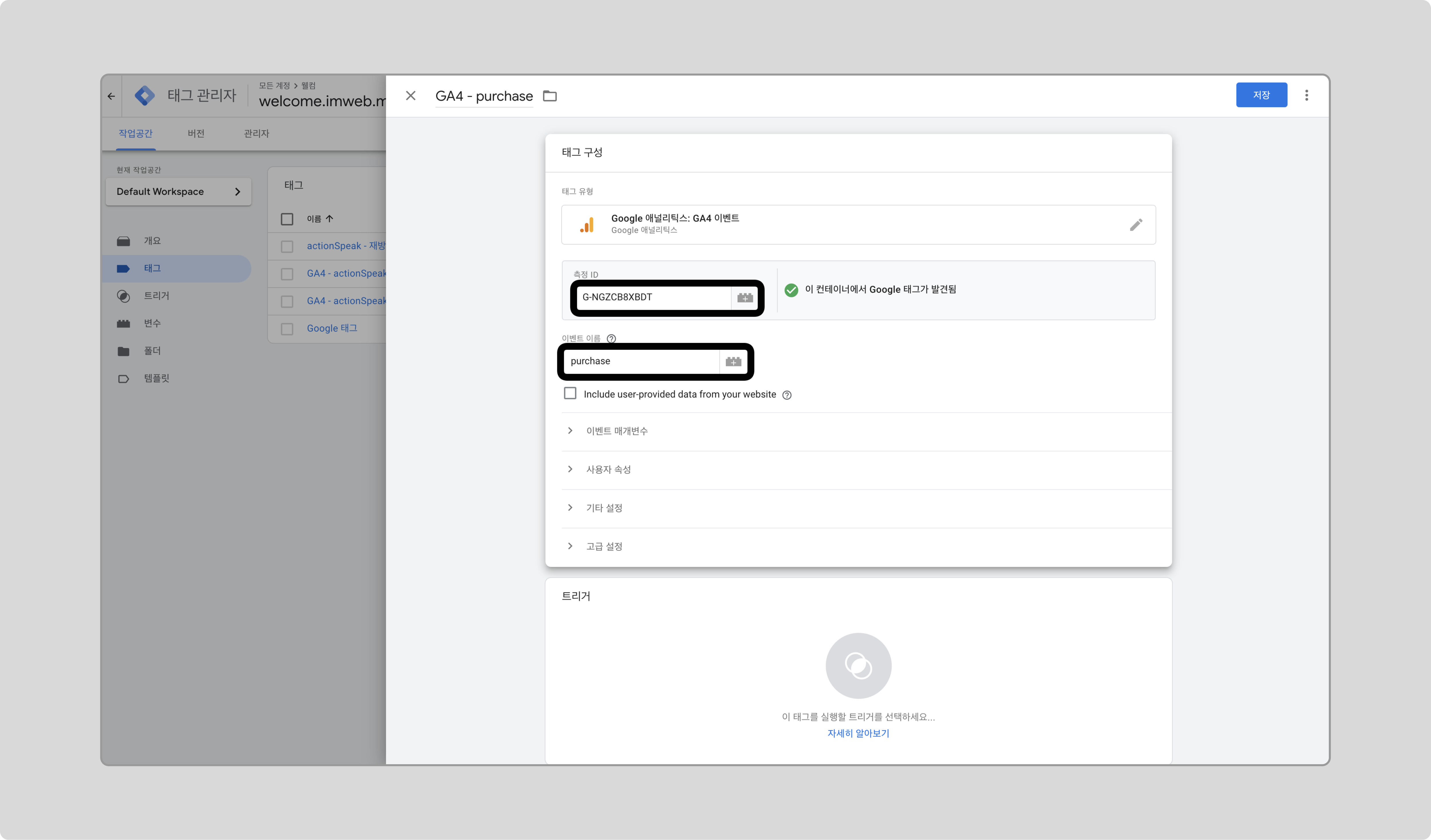
-
이벤트 매개변수를 추가합니다.
- currency: “KRW”
- value: 앞서 추가한 purchaseValue 변수
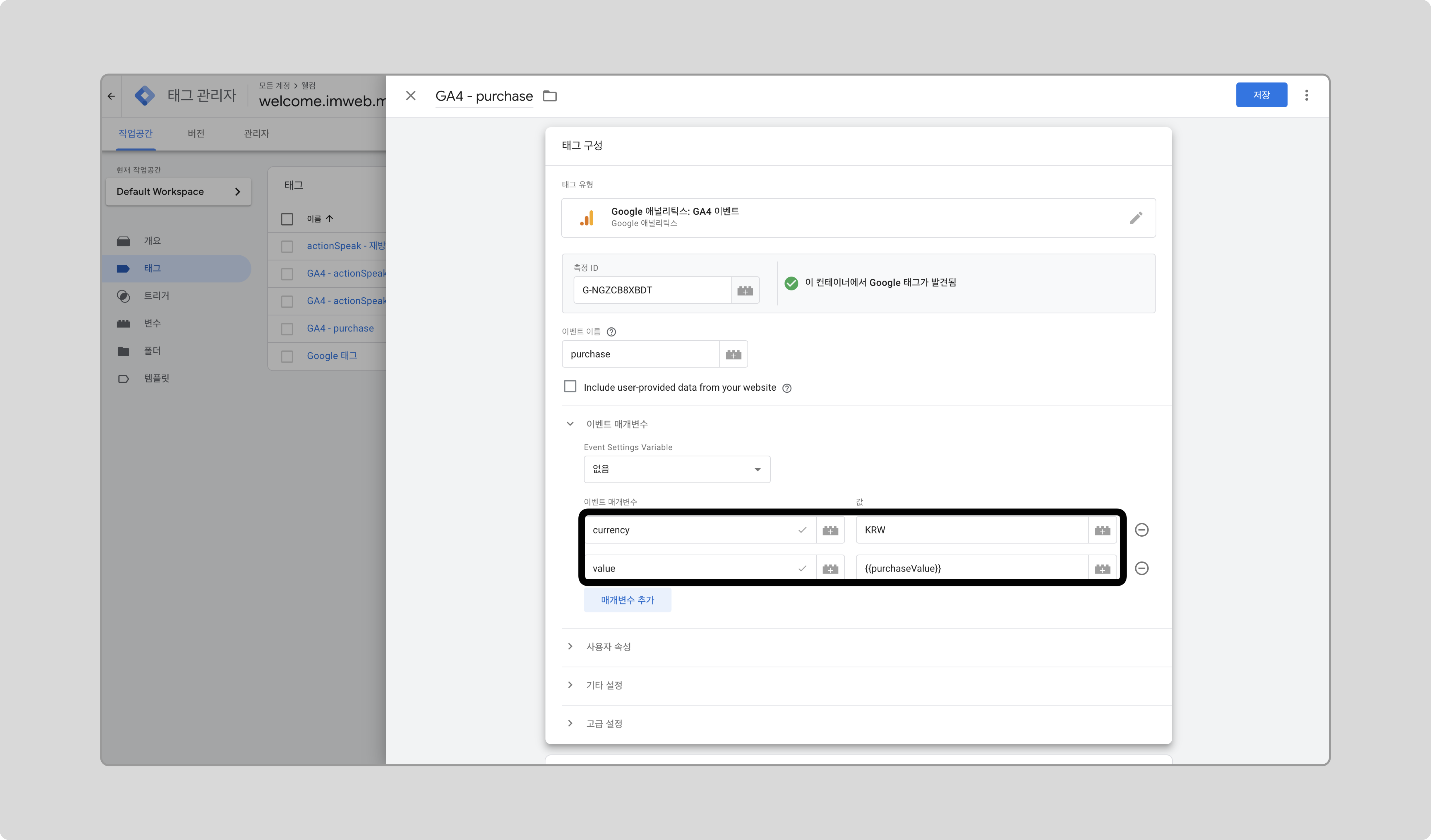
-
트리거로 앞서 추가한 트리거를 선택하고 저장합니다.
BigQuery 데이터로 OLAP 큐브 만들기
📌 데이터가 충분히 수집되었나요?
A/B 테스트를 정확하게 분석하려면, 테스트 기간 동안 신뢰성 있는 표본 크기를 확보하는 것이 중요합니다. actionSpeak는 Ramp-up 방식이 아닌, 처음부터 모든 사용자에게 50% 확률로 test와 control 그룹을 나누어 버킷팅하기 때문에, 데이터 수집 기간과 표본 크기는 테스트 주체가 설정하여 관리해야 합니다.
수집된 데이터는 Google Analytics 4(GA4)에서 이벤트 형태로 저장되며, GA4와 BigQuery를 연동하면 데이터가 BigQuery로 자동 전송됩니다. 연동 방법은 GA4와 BigQuery 연동하기를 참고하세요.
BigQuery로 저장된 데이터를 가공하여 A/B 테스트 분석에 적합한 형태로 변환하는데, 이를 OLAP 큐브라고 합니다.
데이터 미리보기
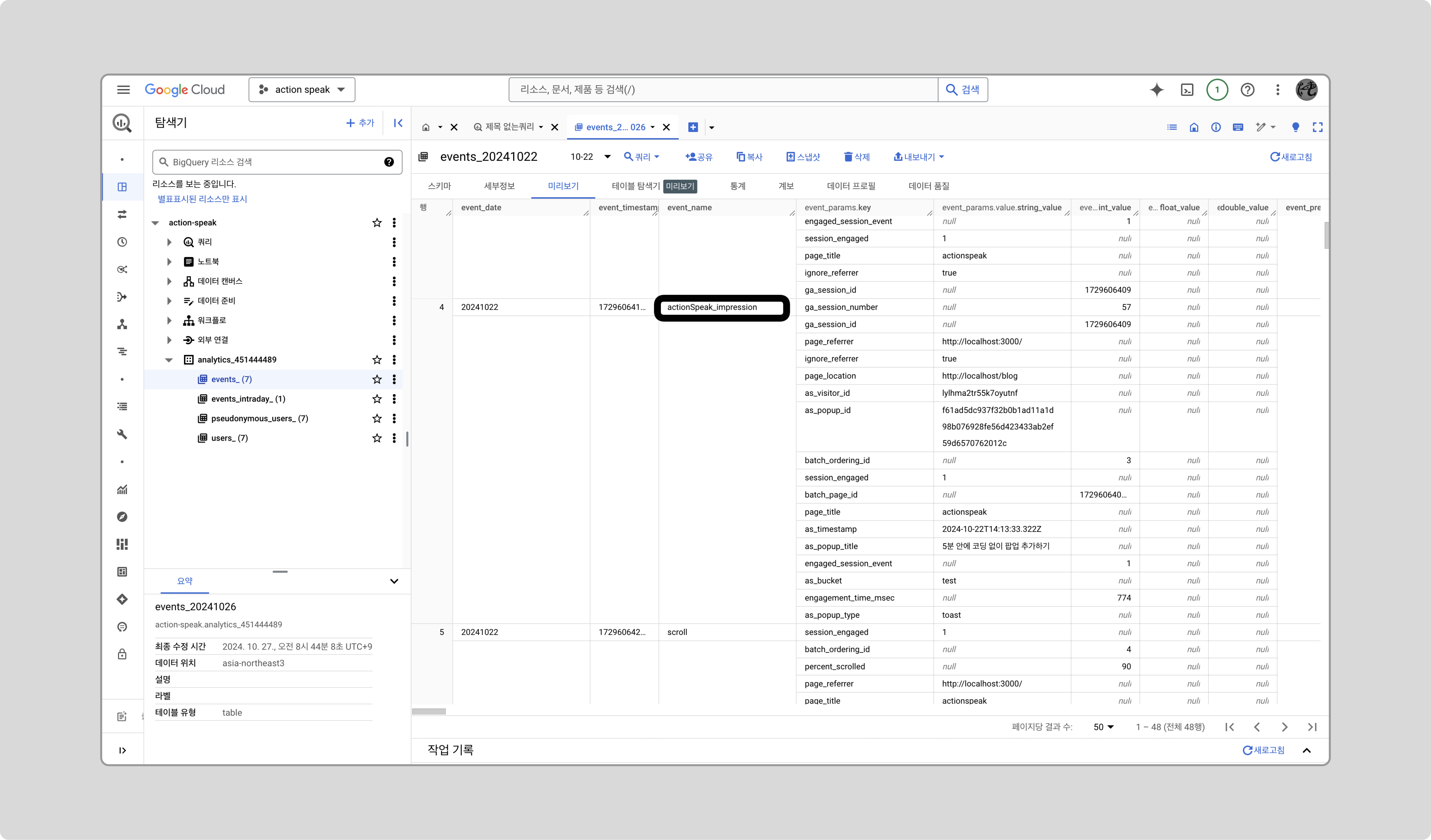
- Google Cloud Bigquery에 들어가서 GA4와 연동한 프로젝트를 선택합니다.
- 연동된 이벤트 테이블을 미리보기하여 GTM에서 설정한 데이터가 잘 저장되고 있는지 확인합니다.
OLAP 큐브 만들기
-
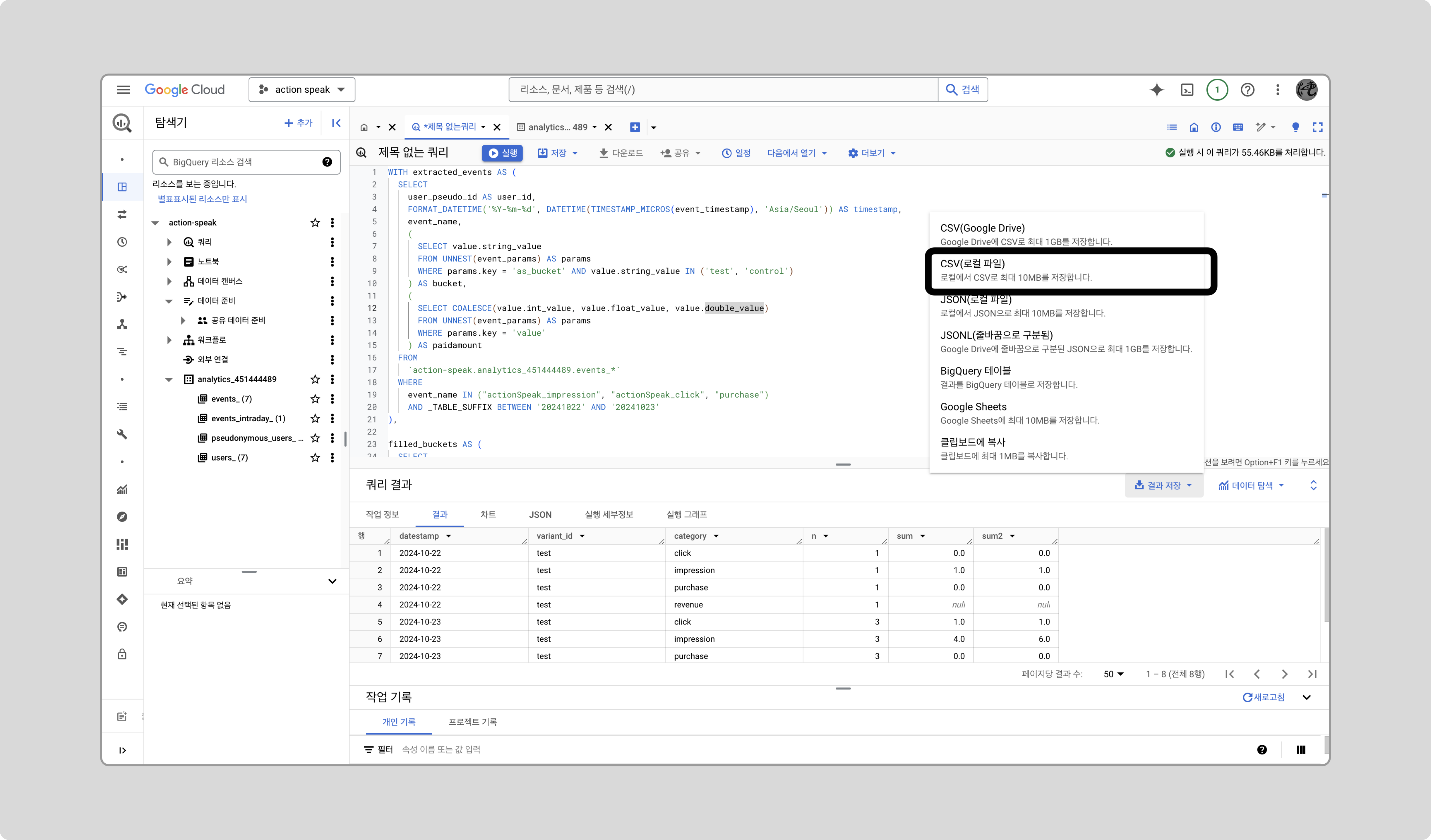
추가 아이콘을 클릭하고, 아래 쿼리 코드를 붙여넣습니다.
WITH extracted_events AS ( SELECT user_pseudo_id AS user_id, FORMAT_DATETIME('%Y-%m-%d', DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Seoul')) AS timestamp, event_name, ( SELECT value.string_value FROM UNNEST(event_params) AS params WHERE params.key = 'as_bucket' AND value.string_value IN ('test', 'control') ) AS bucket, ( SELECT COALESCE(value.int_value, value.float_value, value.double_value) FROM UNNEST(event_params) AS params WHERE params.key = 'value' ) AS paidamount FROM `{project_name}.{analytics_id}.events_*` WHERE event_name IN ("actionSpeak_impression", "actionSpeak_click", "purchase") AND _TABLE_SUFFIX BETWEEN {테스트 시작일} AND {테스트 종료일} ), filled_buckets AS ( SELECT user_id, ARRAY_AGG(bucket ORDER BY CASE bucket WHEN 'test' THEN 1 WHEN 'control' THEN 2 ELSE 3 END LIMIT 1)[OFFSET(0)] AS bucket FROM extracted_events WHERE bucket IS NOT NULL GROUP BY user_id ), filled_events AS ( SELECT e.user_id, e.event_name, e.timestamp, COALESCE(e.bucket, fb.bucket) AS bucket, e.paidamount, CASE WHEN e.event_name = 'actionSpeak_impression' THEN 1 ELSE 0 END AS impression, CASE WHEN e.event_name = 'actionSpeak_click' THEN 1 ELSE 0 END AS click, CASE WHEN e.event_name = 'purchase' THEN 1 ELSE 0 END AS purchase FROM extracted_events e LEFT JOIN filled_buckets fb ON e.user_id = fb.user_id ), variant_daily_summary AS ( SELECT bucket AS variant_id, user_id, timestamp AS datestamp, COUNTIF(event_name = 'actionSpeak_impression') AS actionSpeak_impressions, SUM(click) AS actionSpeak_clicks, SUM(CASE WHEN purchase = 1 THEN 1 ELSE 0 END) AS num_of_purchases, SUM(CASE WHEN purchase = 1 THEN paidamount ELSE 0 END) AS revenue FROM filled_events GROUP BY bucket, user_id, timestamp ) -- OLAP Cube 생성 SELECT datestamp, variant_id, 'impression' category, COUNT(1) AS n, SUM(actionSpeak_impressions) AS sum, SUM(actionSpeak_impressions * actionSpeak_impressions) AS sum2 FROM variant_daily_summary vds GROUP BY 1, 2, 3 UNION ALL SELECT datestamp, variant_id, 'click' category, COUNT(1) AS n, SUM(actionSpeak_clicks) AS sum, SUM(actionSpeak_clicks * actionSpeak_clicks) AS sum2 FROM variant_daily_summary vds GROUP BY 1, 2, 3 UNION ALL SELECT datestamp, variant_id, 'purchase' category, COUNT(1) AS n, SUM(num_of_purchases) AS sum, SUM(num_of_purchases * num_of_purchases) AS sum2 FROM variant_daily_summary vds WHERE num_of_purchases > 0 GROUP BY 1, 2, 3 UNION ALL SELECT datestamp, variant_id, 'revenue' category, COUNT(1) AS n, SUM(revenue) AS sum, SUM(revenue * revenue) AS sum2 FROM variant_daily_summary vds WHERE revenue > 0 GROUP BY 1, 2, 3 ORDER BY datestamp, variant_id, category;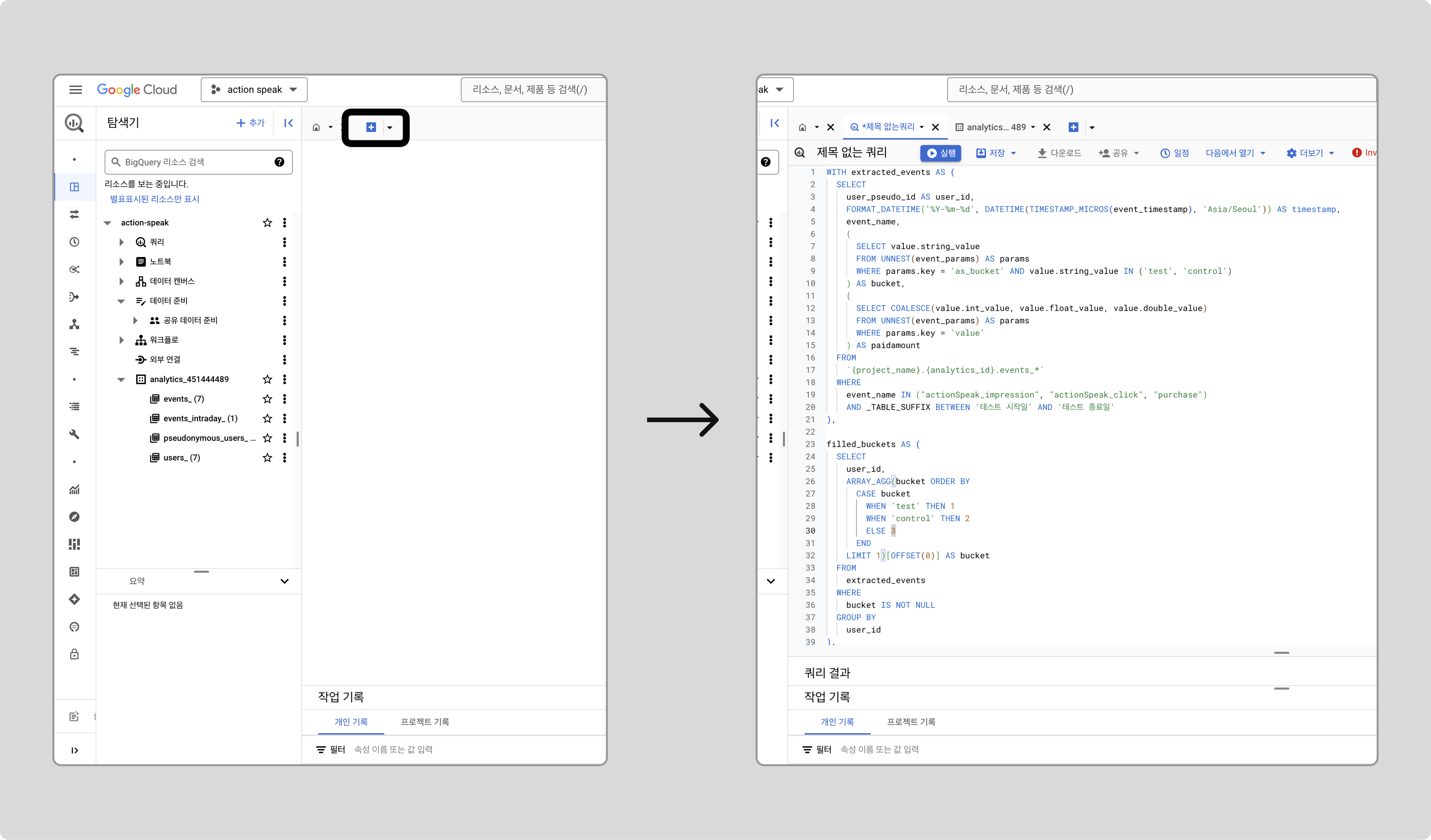
-
데이터 세트 ID와 테스트 시작일, 종료일을 수정하고 쿼리를 실행합니다.
데이터 세트 ID는 데이터 세트 정보에서 확인할 수 있습니다.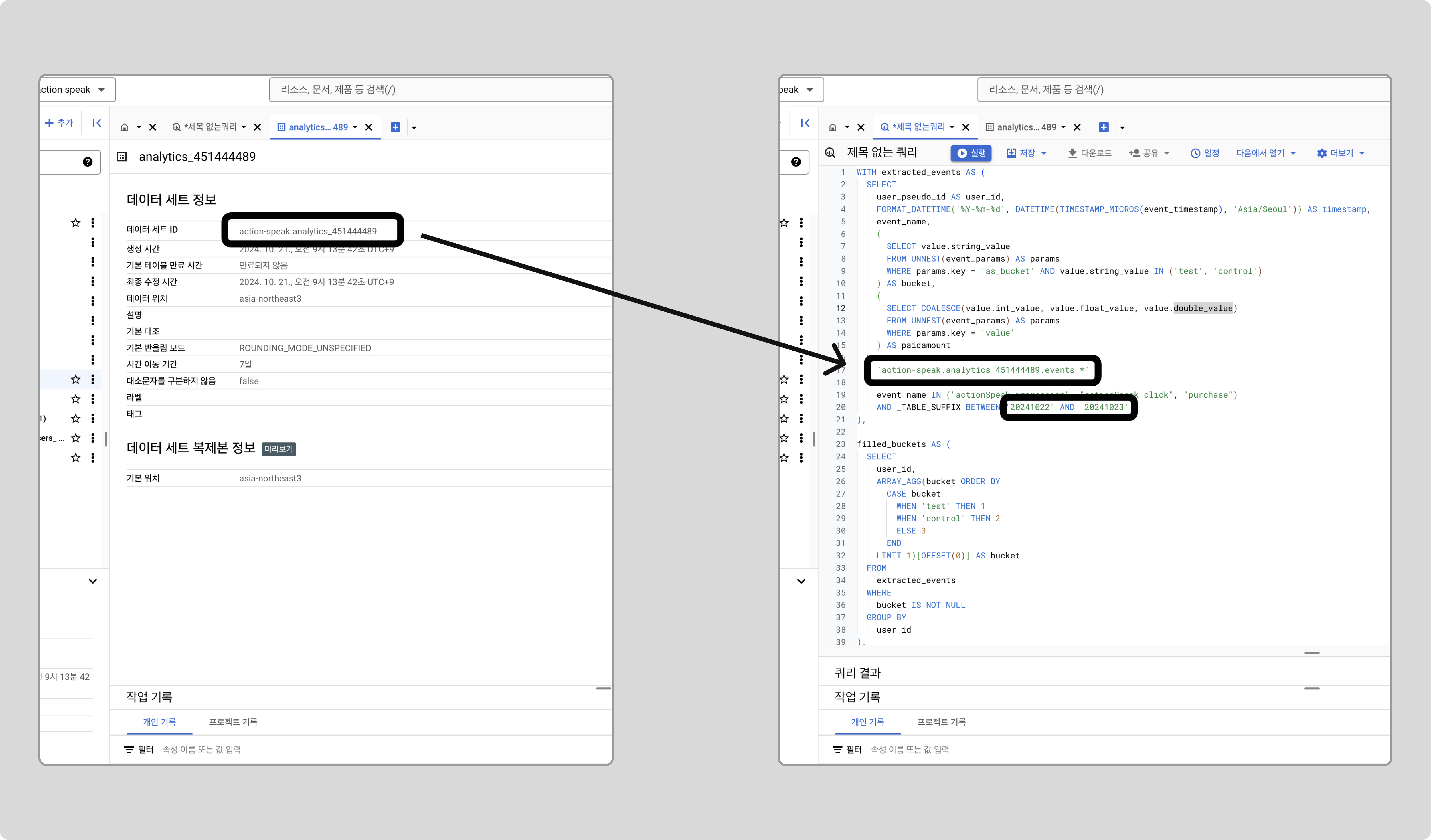
-
결과를 CSV 파일로 저장합니다.
Tableau로 테스트 결과 시각화하기
BigQuery에서 가공한 OLAP 큐브 데이터를 Tableau로 시각화하여 A/B 테스트 결과를 직관적으로 파악할 수 있습니다.
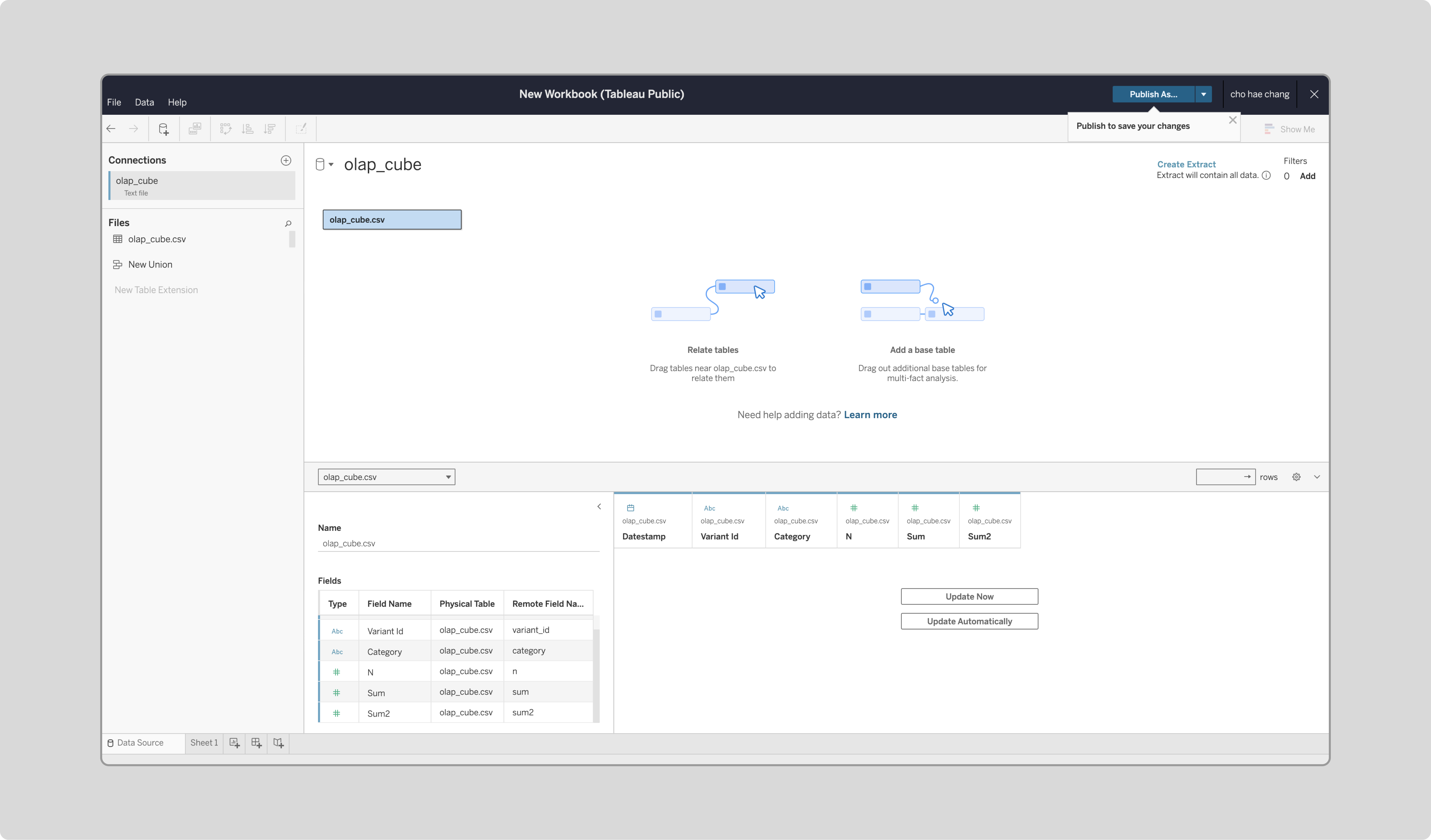
OLAP 큐브 데이터 가져오기
-
Tableau public에 접속해 계정을 생성한 후, [Create] > [Web Authoring]를 클릭합니다.
-
앞서 BigQuery에서 CSV 파일로 저장한 데이터를 업로드합니다.
트래픽 균등성 검증
A/B 테스트에서 신뢰성 있는 결과를 얻으려면 test와 control 그룹에 균등하게 트래픽이 분배되었는지 확인이 필요합니다.
📌 트래픽 균등성 확인을 위한 통계 기법: Proportions Z-test
Proportions Z-test를 통해 test와 control 그룹이 50:50 비율로 분배되었는지 검증합니다. Z-score가 ±1.96 범위 내에 있으면 두 그룹의 트래픽이 균등하게 분배된 것으로 간주합니다.
필드 값 생성
-
하단 Sheet를 클릭합니다.
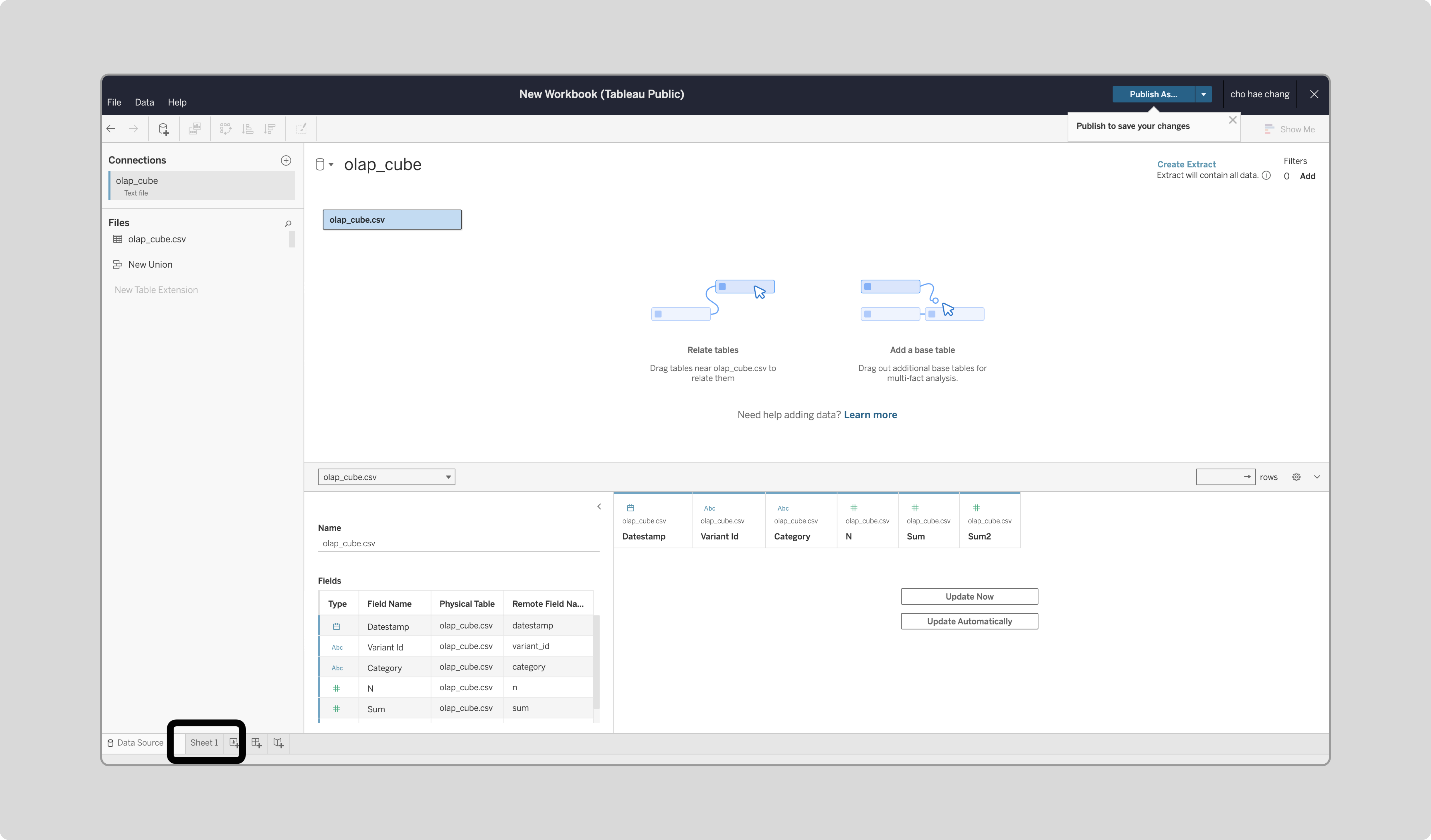
-
Create Calculated Field를 클릭합니다.
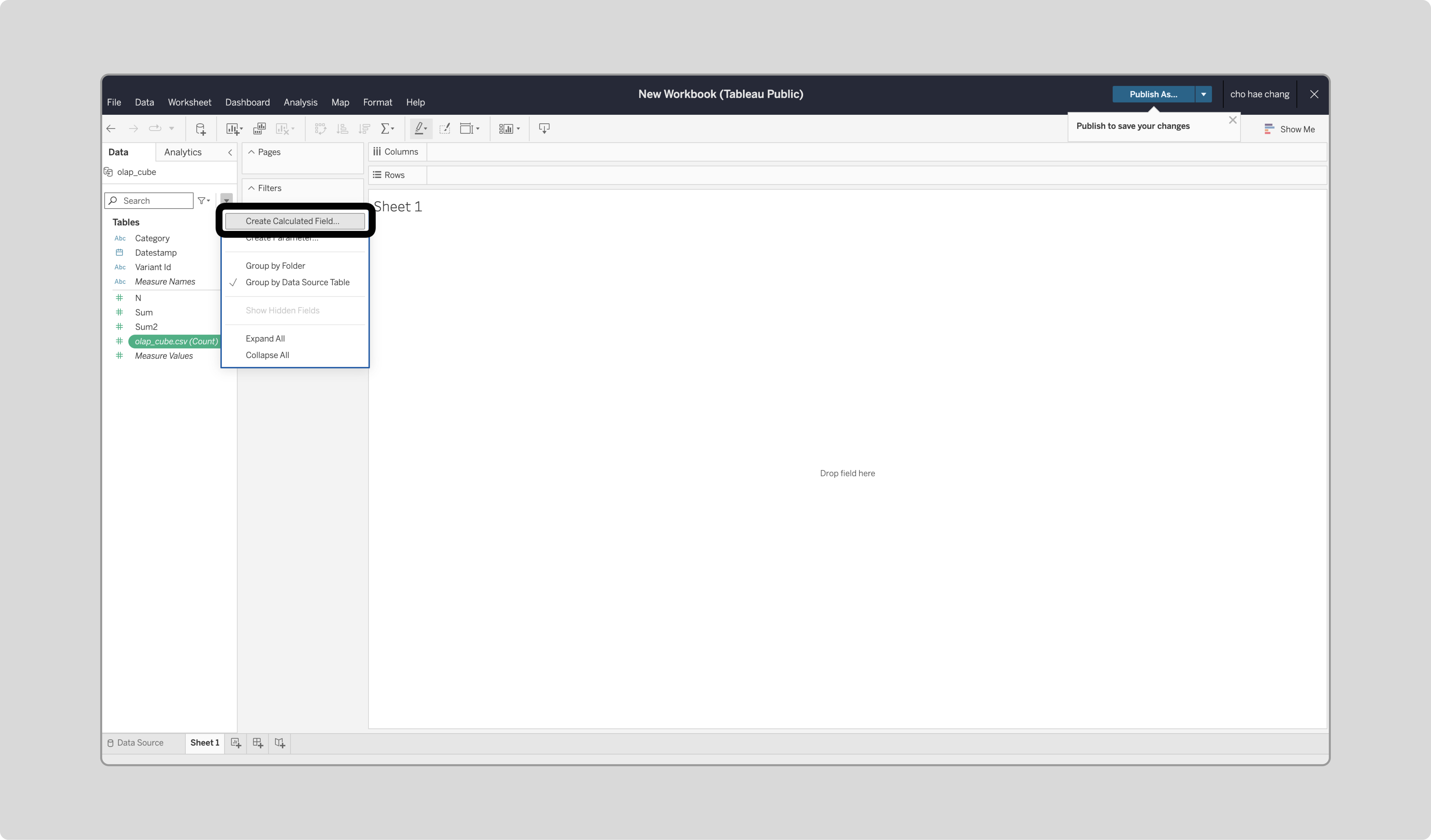
-
‘테스트_사용자수’ 필드를 생성합니다.
test 그룹의 사용자 수를 계산합니다.SUM(IF [Variant Id] = 'test' THEN [N] ELSE 0 END)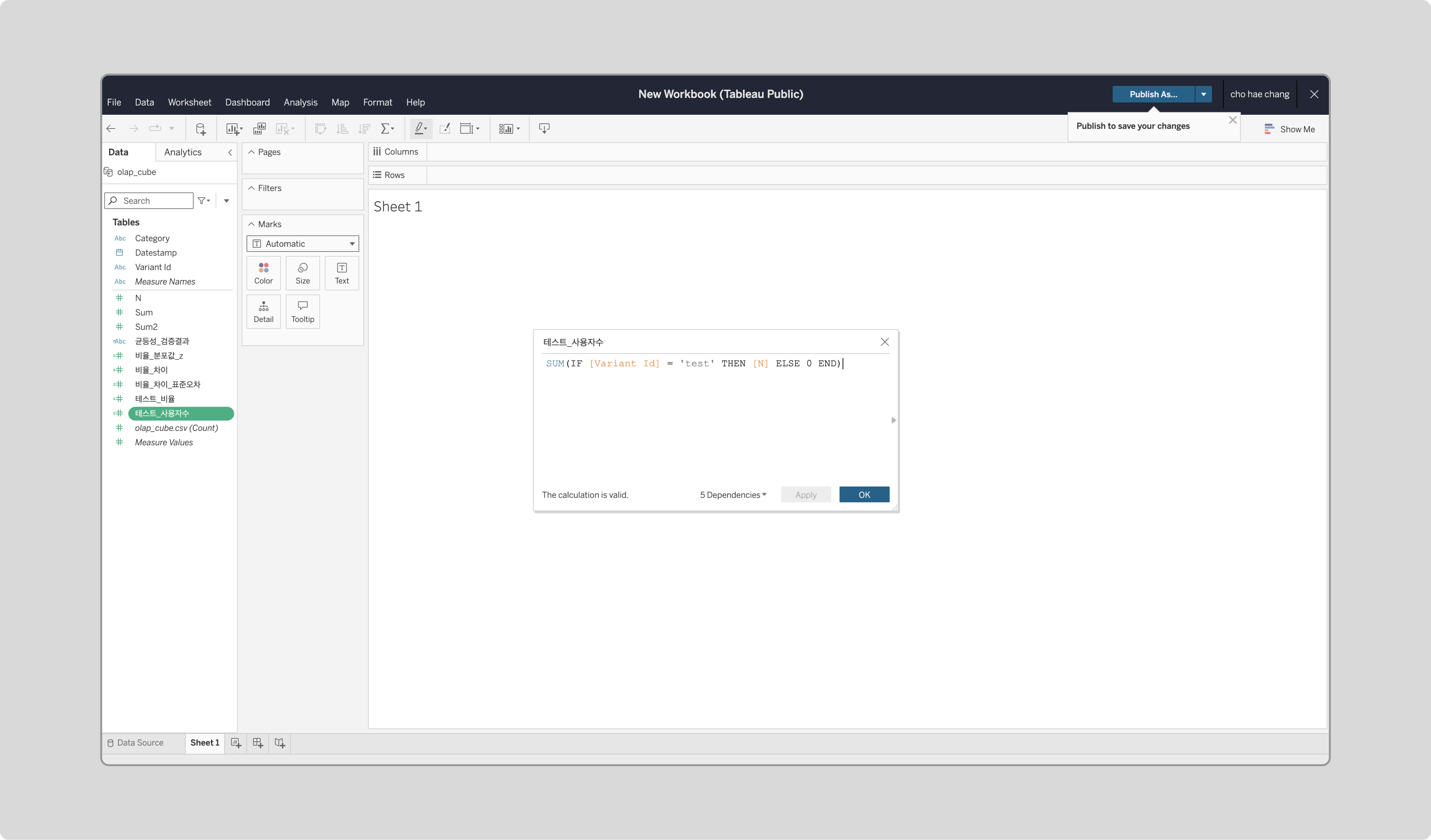
-
동일한 방식으로 ‘테스트_비율’ 필드를 생성합니다.
전체 사용자 중 test 그룹에 할당된 비율을 계산합니다.[테스트_사용자수] / SUM([N]) -
‘비율_차이’ 필드를 생성합니다.
이상적인 비율인 50%와의 차이를 계산합니다[테스트_비율] - 0.5 -
‘비율_차이_표준오차’ 필드를 생성합니다.
비율 차이의 표준 오차를 계산합니다.SQRT(([테스트_비율] * (1 - [테스트_비율])) / SUM([N])) -
‘비율_분포값_z’ 필드를 생성합니다.
test와 control 그룹의 50:50 분배 여부를 확인하는 지표입니다.[비율_차이] / [비율_차이_표준오차] -
‘균등성_검증결과’ 필드를 생성합니다.
Z-score가 ±1.96 범위 안에 있으면 "균등", 벗어나면 "불균등"으로 표시합니다.IF ABS([비율_분포값_z]) > 1.96 THEN "불균등" ELSE "균등" END -
모든 필드가 추가되었는지 확인합니다.
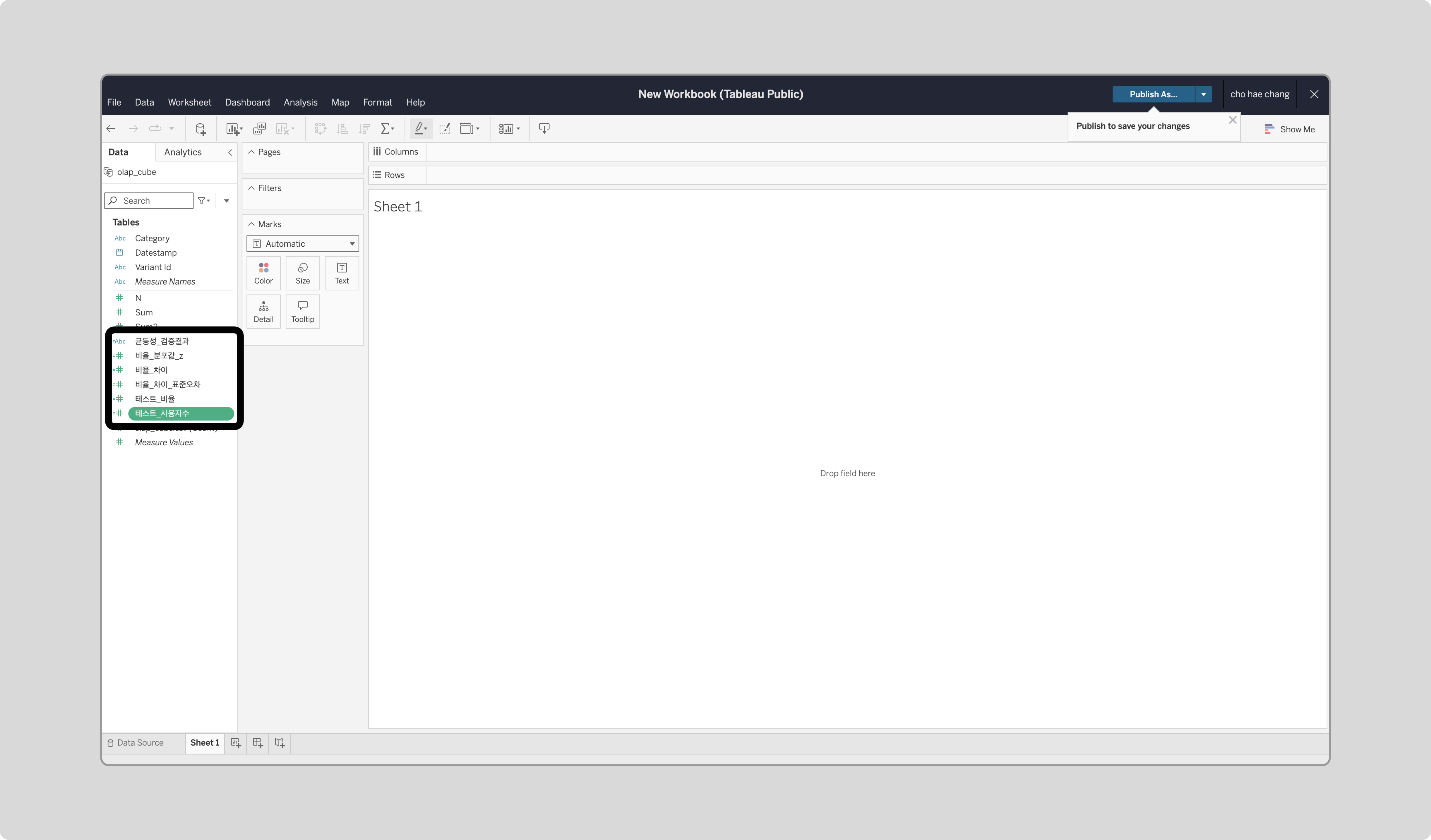
시각화
-
‘테스트_사용자수’와 ‘테스트_비율’는 Rows로, Datestamp는 Columns로 드래그합니다.
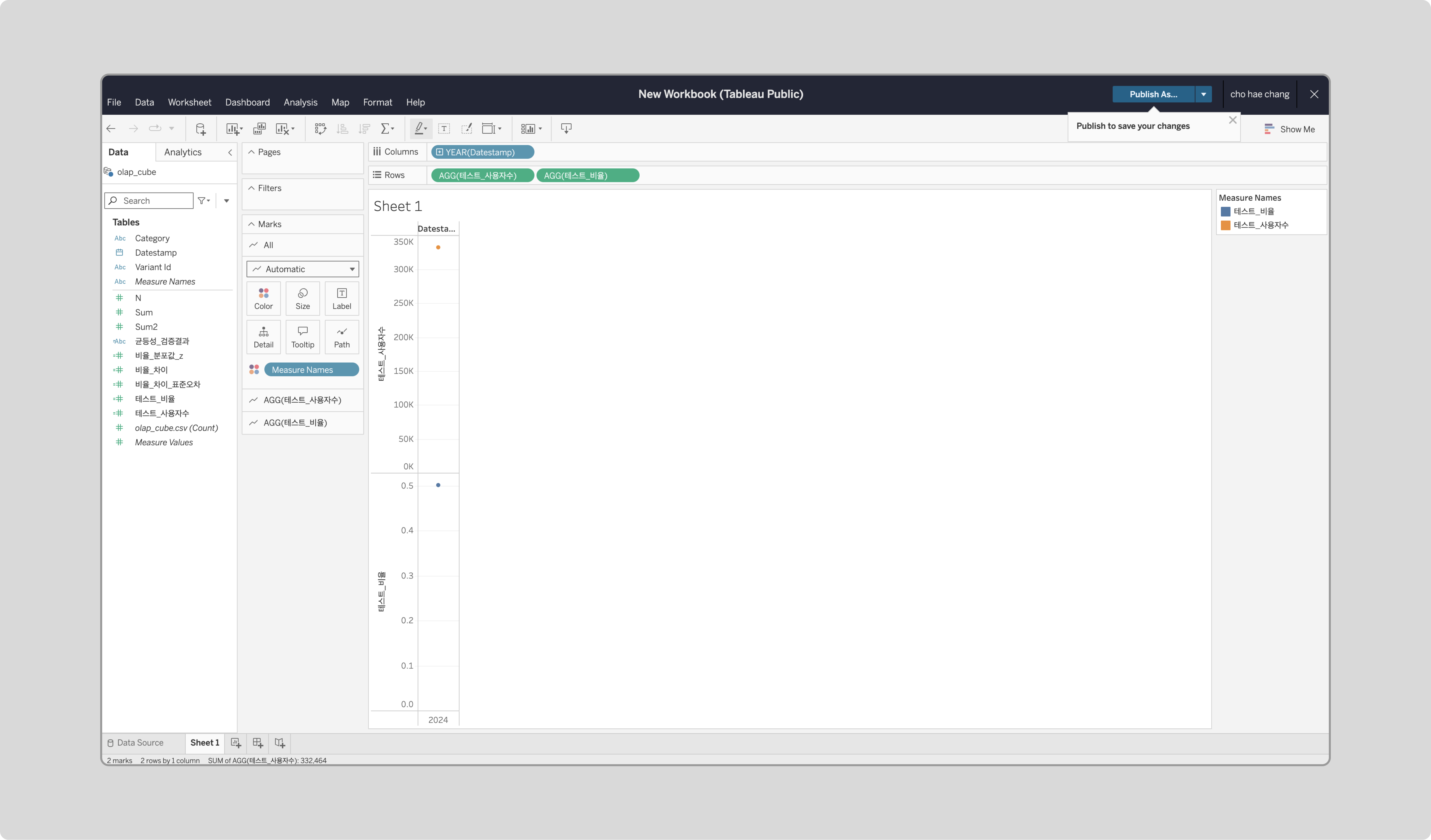
-
‘테스트_비율’에 우클릭해 ‘Dual Axis’를 선택합니다.
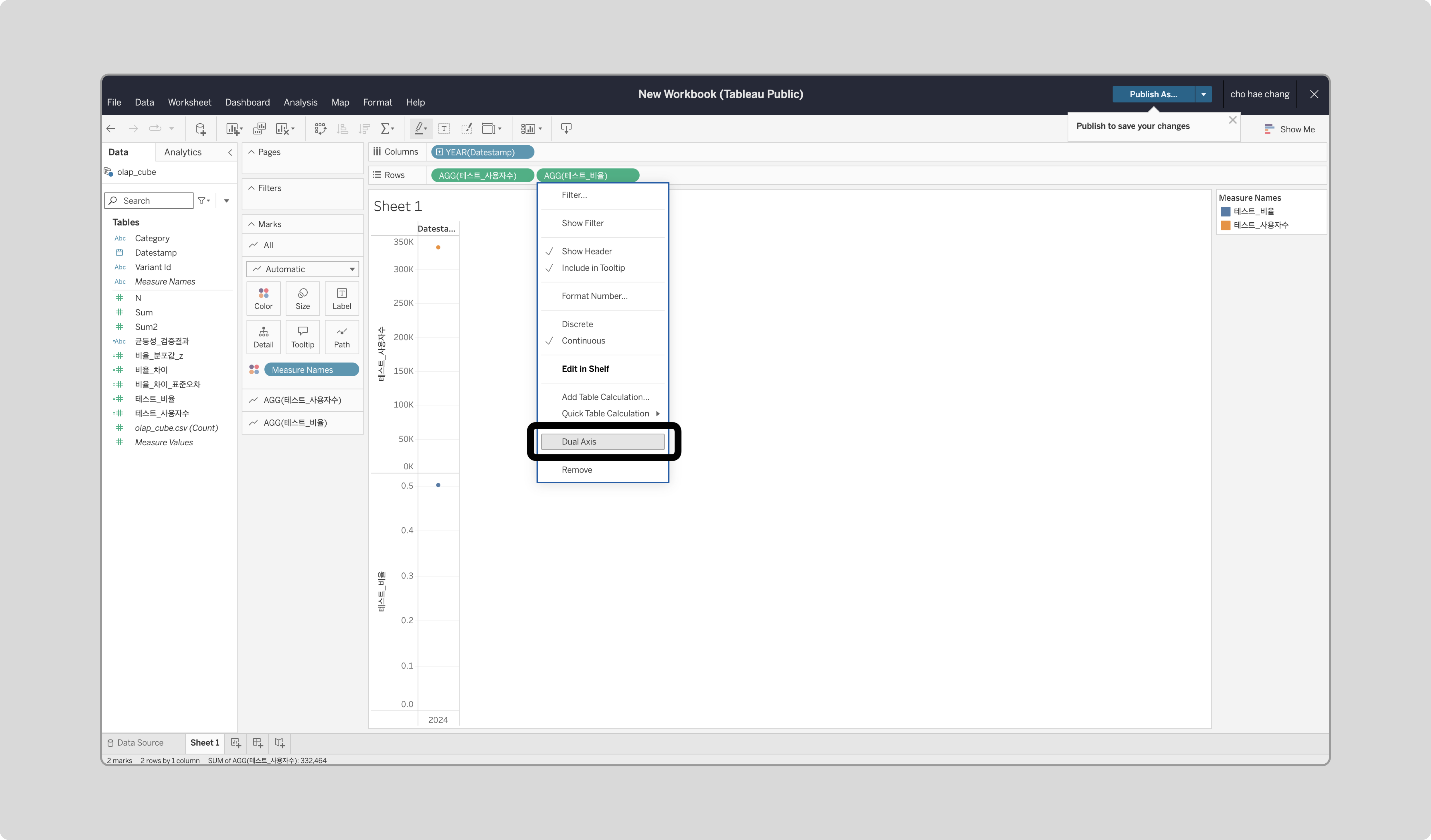
-
‘Datestamp’를 우측해 ‘Day’를 선택합니다.
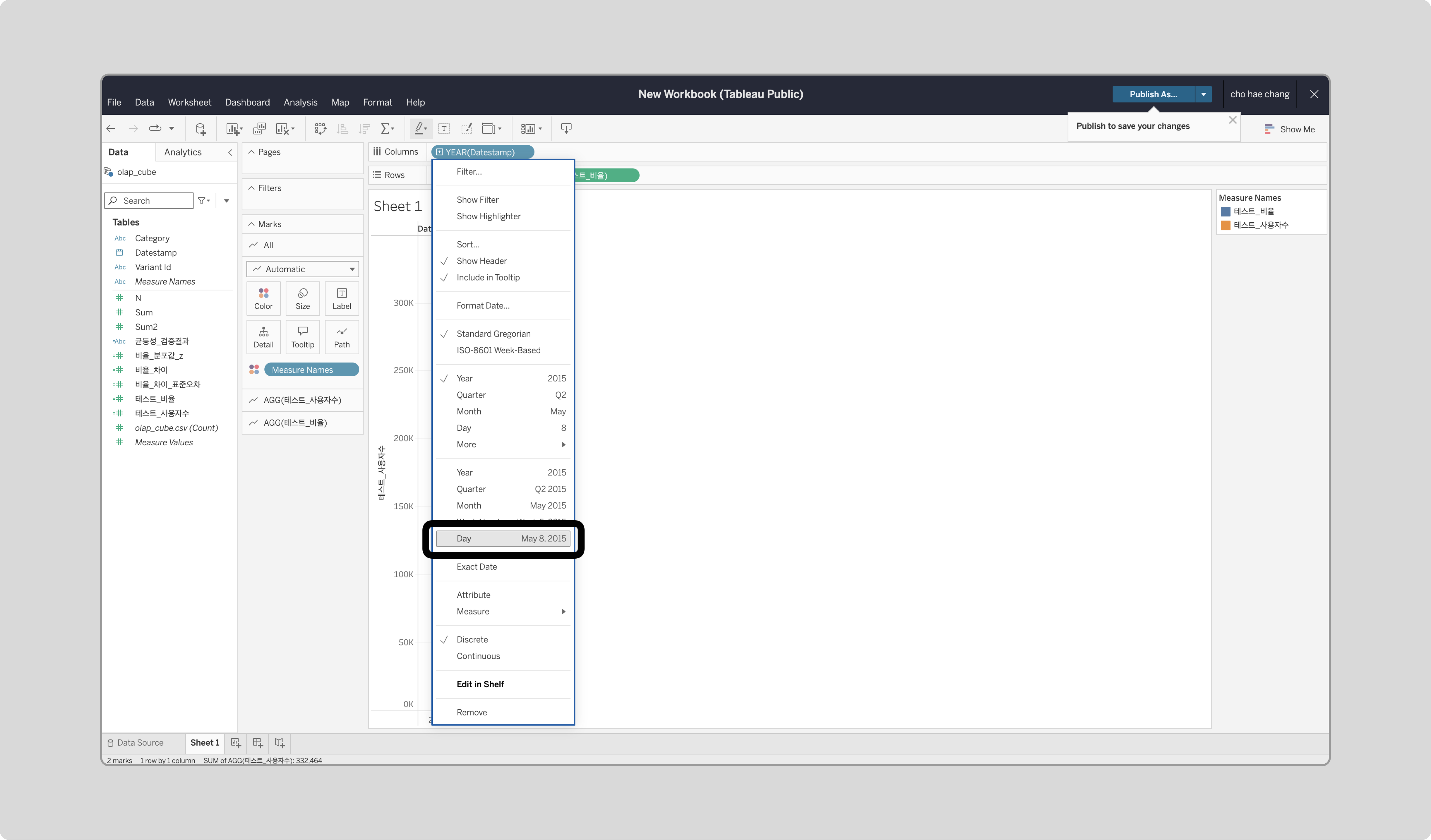
-
‘테스트_사용자수’의 차트 모양과 색을 수정합니다.
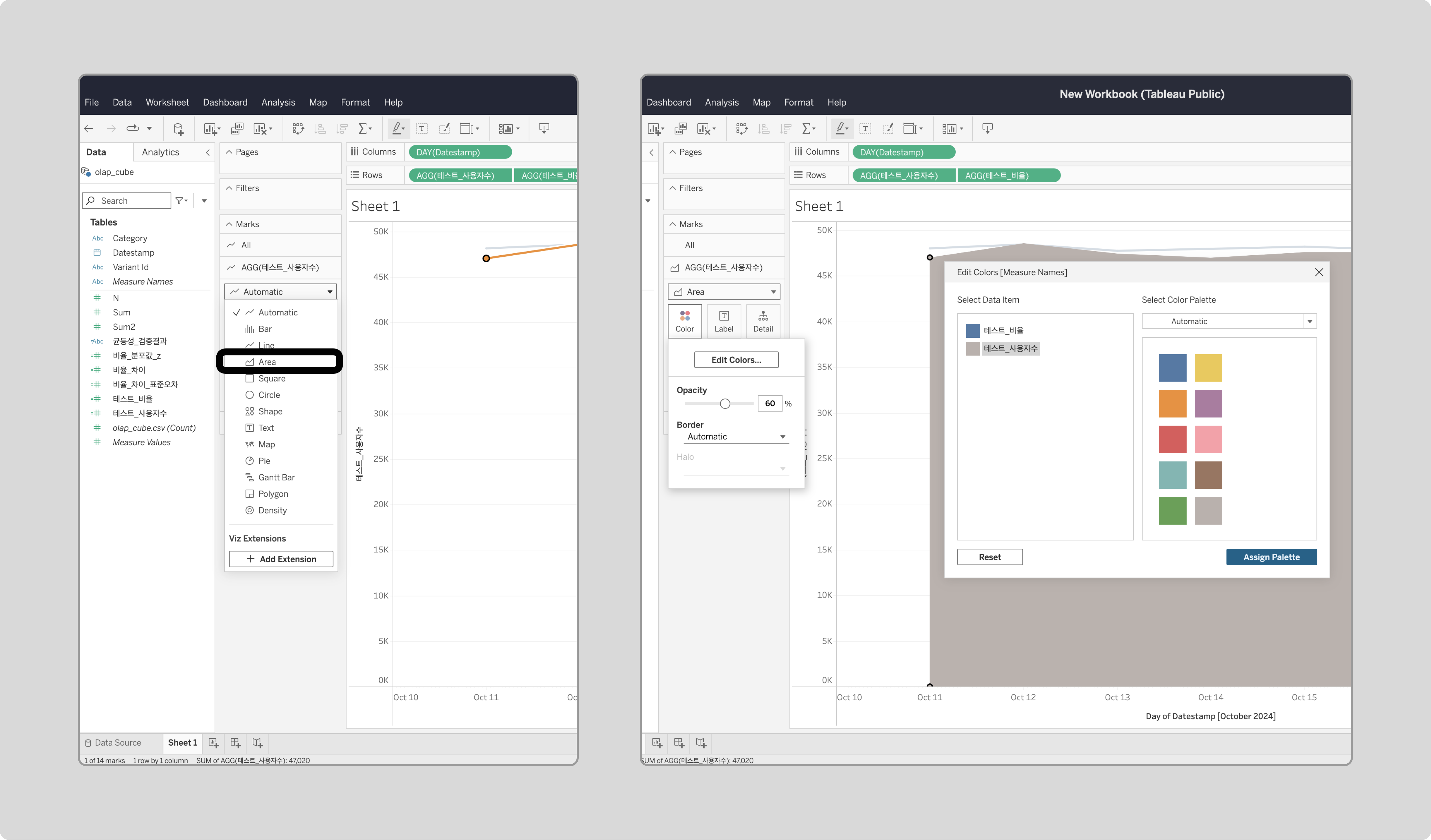
-
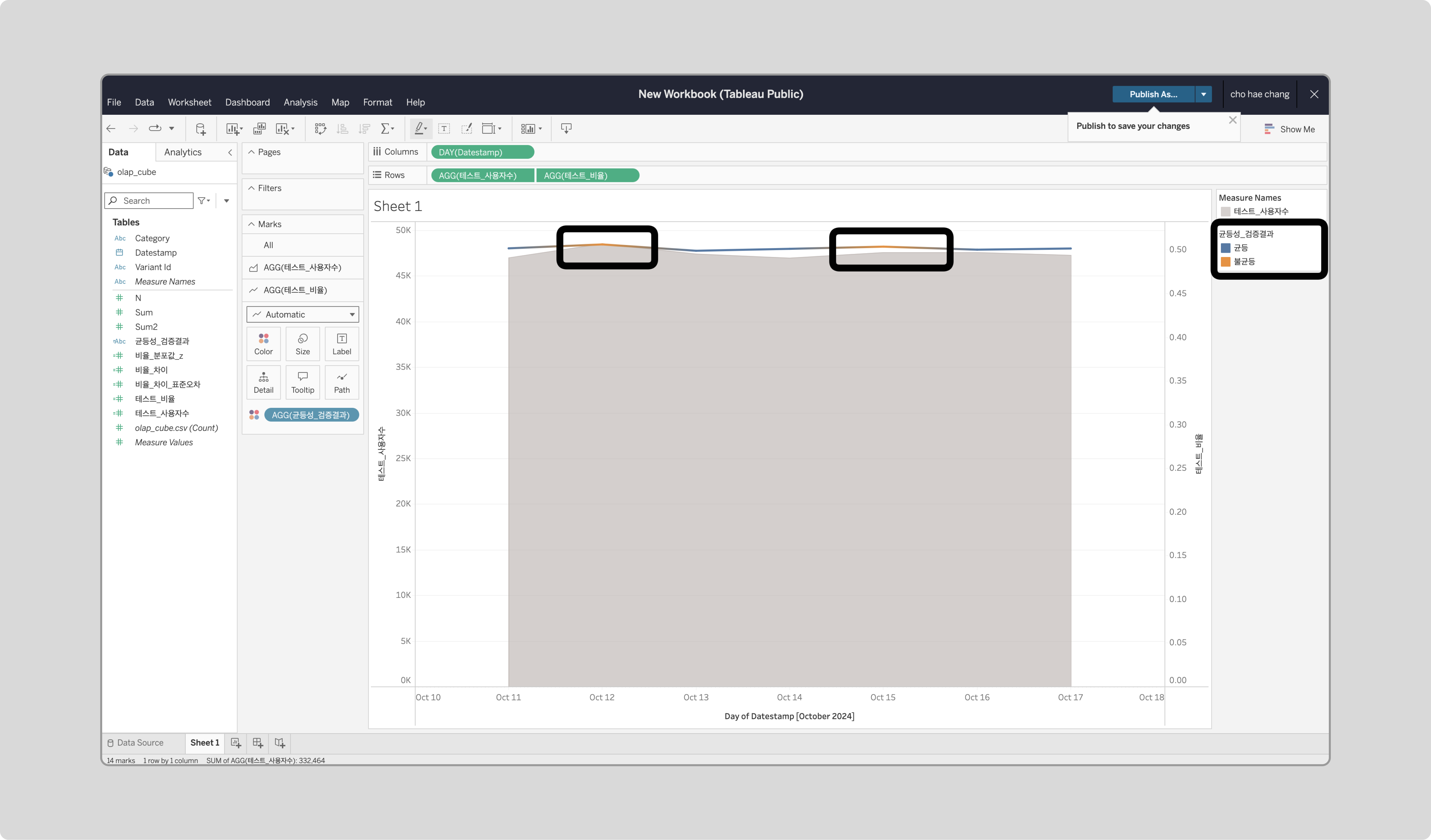
‘균등성_검증결과’를 ‘테스트_비율’의 Color에 드래그합니다.
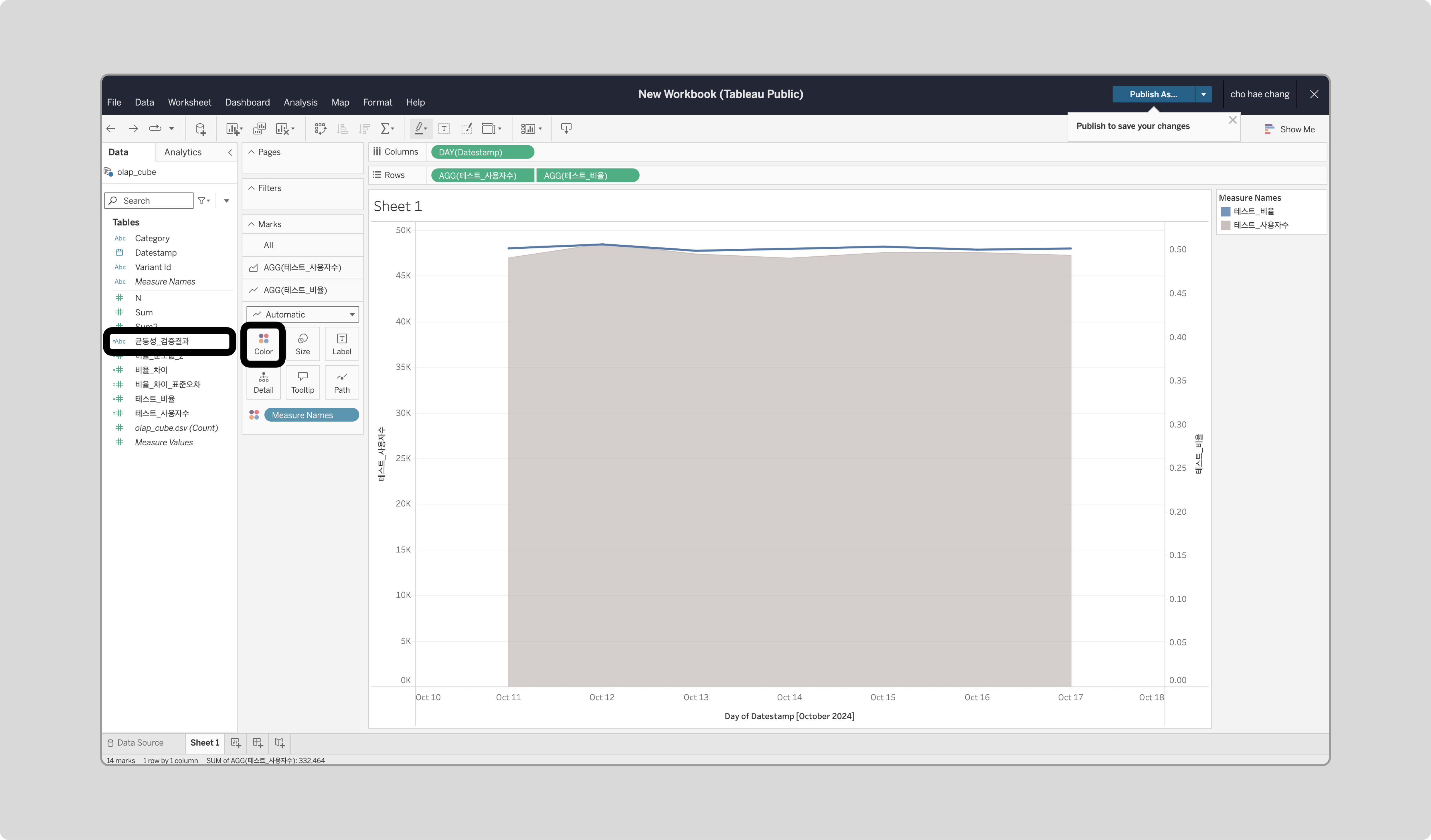
결과 분석
시각화된 데이터를 통해 트래픽 분배가 균등한지 확인합니다. 특정 기간에 Z-score가 ±1.96을 벗어나는 구간은 불균등 구간으로 간주하며, 해당 데이터는 해석에 영향을 줄 수 있어 재테스트가 권장됩니다.
테스트 결과 유의성 검증
📌 테스트 결과 유의성 검증을 위한 통계 기법: Two-Sample T-Test
Two-Sample T-Test는 test와 control 그룹의 평균 차이를 비교해 유의미한 차이가 있는지 확인하는 방법입니다. Z-score가 -1.96보다 작으면 control 그룹이 우세, 1.96보다 크면 test 그룹이 우세로 간주합니다.
필드 값 생성
-
‘컨트롤_사용자수’ 필드를 생성합니다.
control 그룹의 사용자 수를 계산합니다.SUM(if [Variant Id]='control' then [N] end) -
‘컨트롤_평균’ 필드를 생성합니다.
control 그룹의 평균 값을 계산합니다.SUM(IF [Variant Id]='control' THEN [Sum] END) / [컨트롤_사용자수] -
‘컨트롤_분산’ 필드를 생성합니다.
control 그룹의 분산을 계산합니다.SUM(IF [Variant Id]='control' THEN [Sum2] END) / [컨트롤_사용자수] - [컨트롤_평균]^2 -
‘테스트_평균’ 필드를 생성합니다.
test 그룹의 평균 값을 계산합니다.SUM(IF [Variant Id]='test' THEN [Sum] END) / [테스트_사용자수] -
‘테스트_분산’ 필드를 생성합니다.
test 그룹의 분산을 계산합니다.SUM(IF [Variant Id]='test' THEN [Sum2] END) / [테스트_사용자수] - [테스트_평균]^2 -
‘평균_차이’ 필드를 생성합니다.
test와 control 그룹의 평균 차이를 계산합니다.[테스트_평균] - [컨트롤_평균] -
‘평균_차이_표준오차’ 필드를 생성합니다.
두 그룹 간 평균 차이에 대한 표준 오차입니다.SQRT([테스트_분산] / [테스트_사용자수] + [컨트롤_분산] / [컨트롤_사용자수]) -
‘차이_분포값_z’ 필드를 생성합니다.
두 그룹의 평균 차이에 대한 Z-score로, 통계적으로 유의미한 차이를 확인하는 지표입니다.[평균_차이] / [평균_차이_표준오차] -
‘유의성_검증결과’ 필드를 생성합니다.
Z-score가 ±1.96 범위를 벗어나면 "Test 우세" 또는 "Control 우세", 범위 내에 있으면 "차이 없음"으로 표시합니다.IF [차이_분포값_z] > 1.96 THEN "Test 우세" ELSEIF [차이_분포값_z] < -1.96 THEN "Control 우세" ELSE "차이 없음" END -
모든 필드가 추가되었는지 확인합니다.
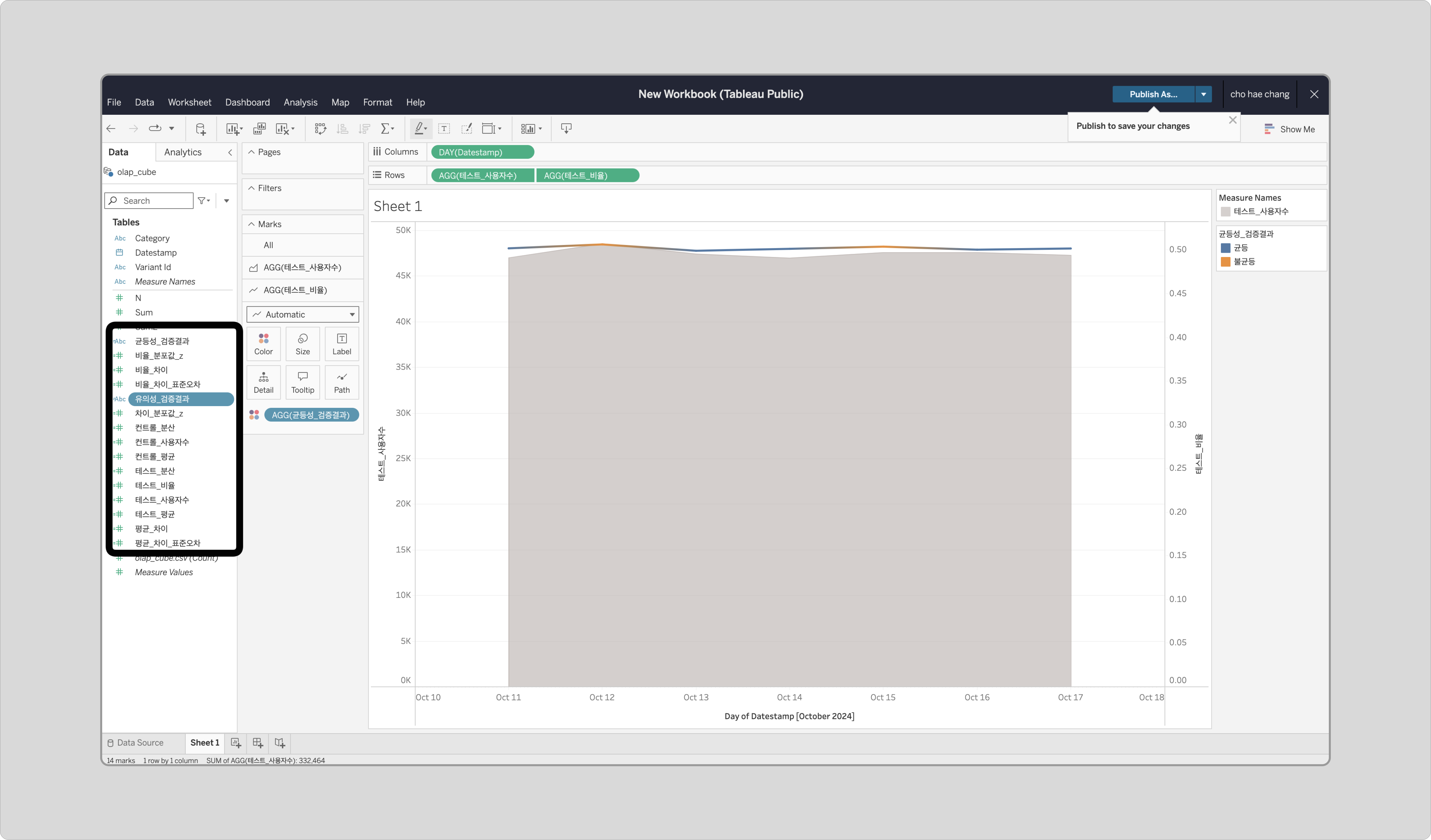
시각화
-
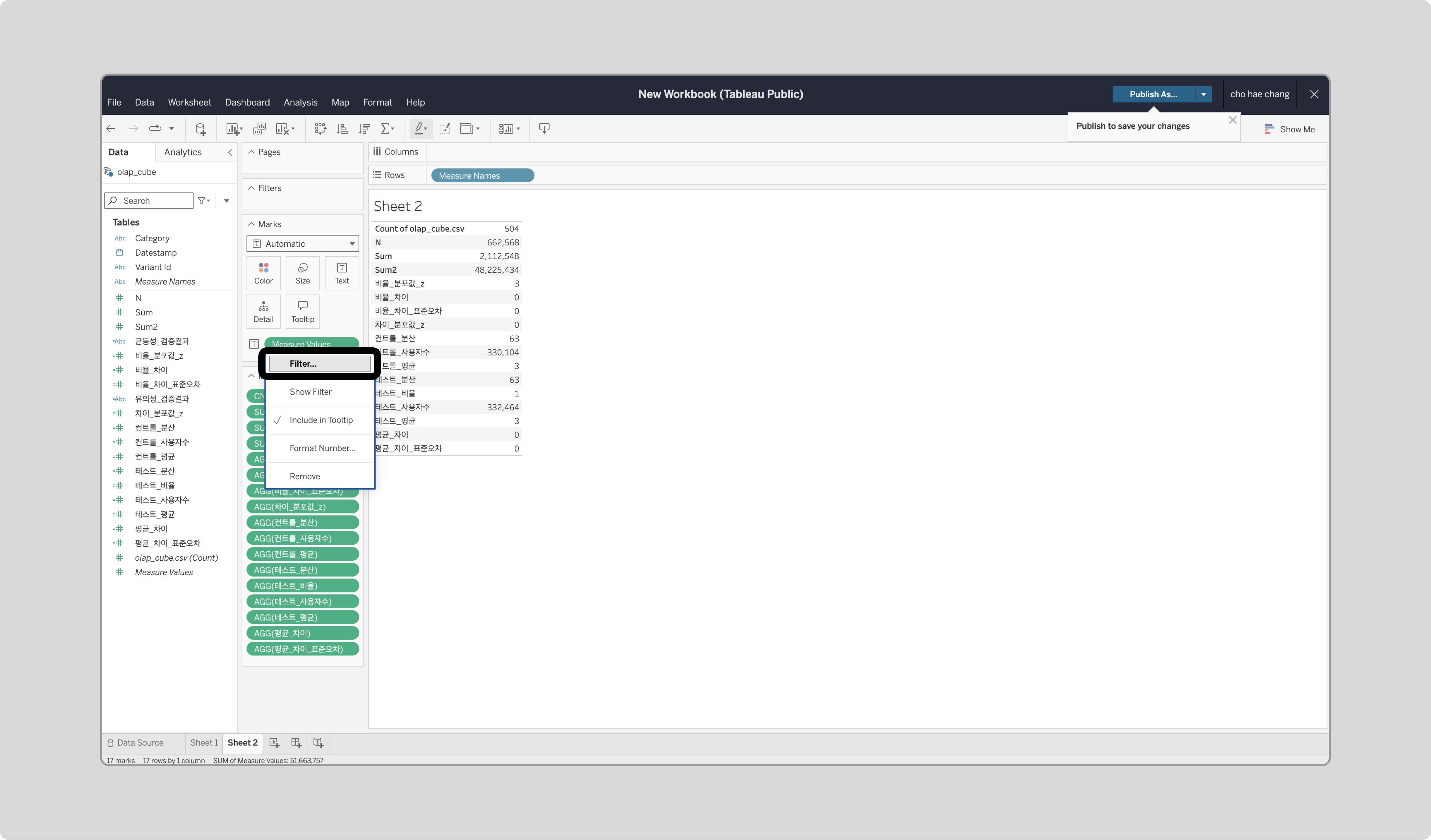
새 Sheet를 열고, ‘Measure Names’를 Rows로, ‘Measure Values’를 Marks의 Text로 드래그합니다.
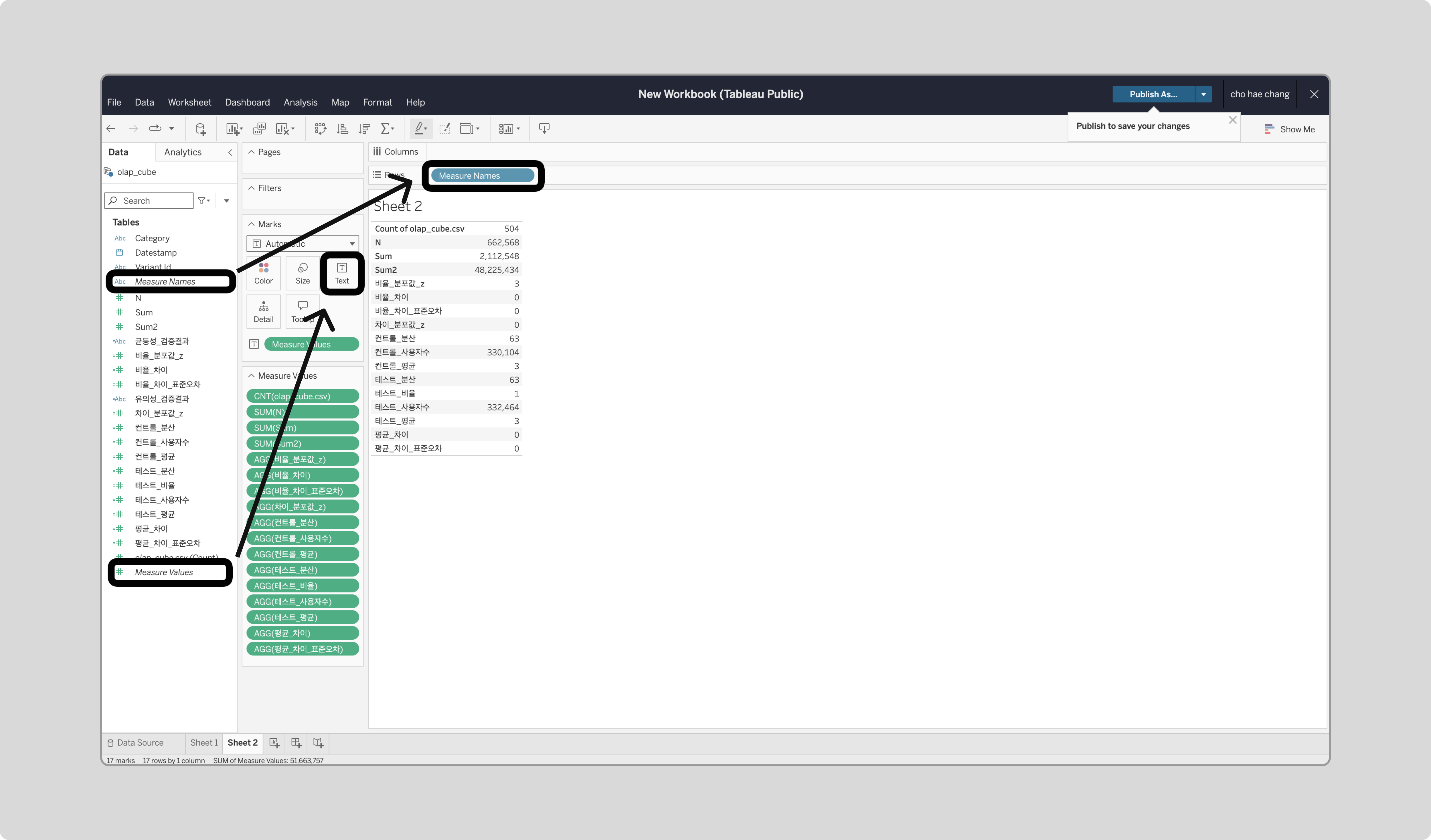
-
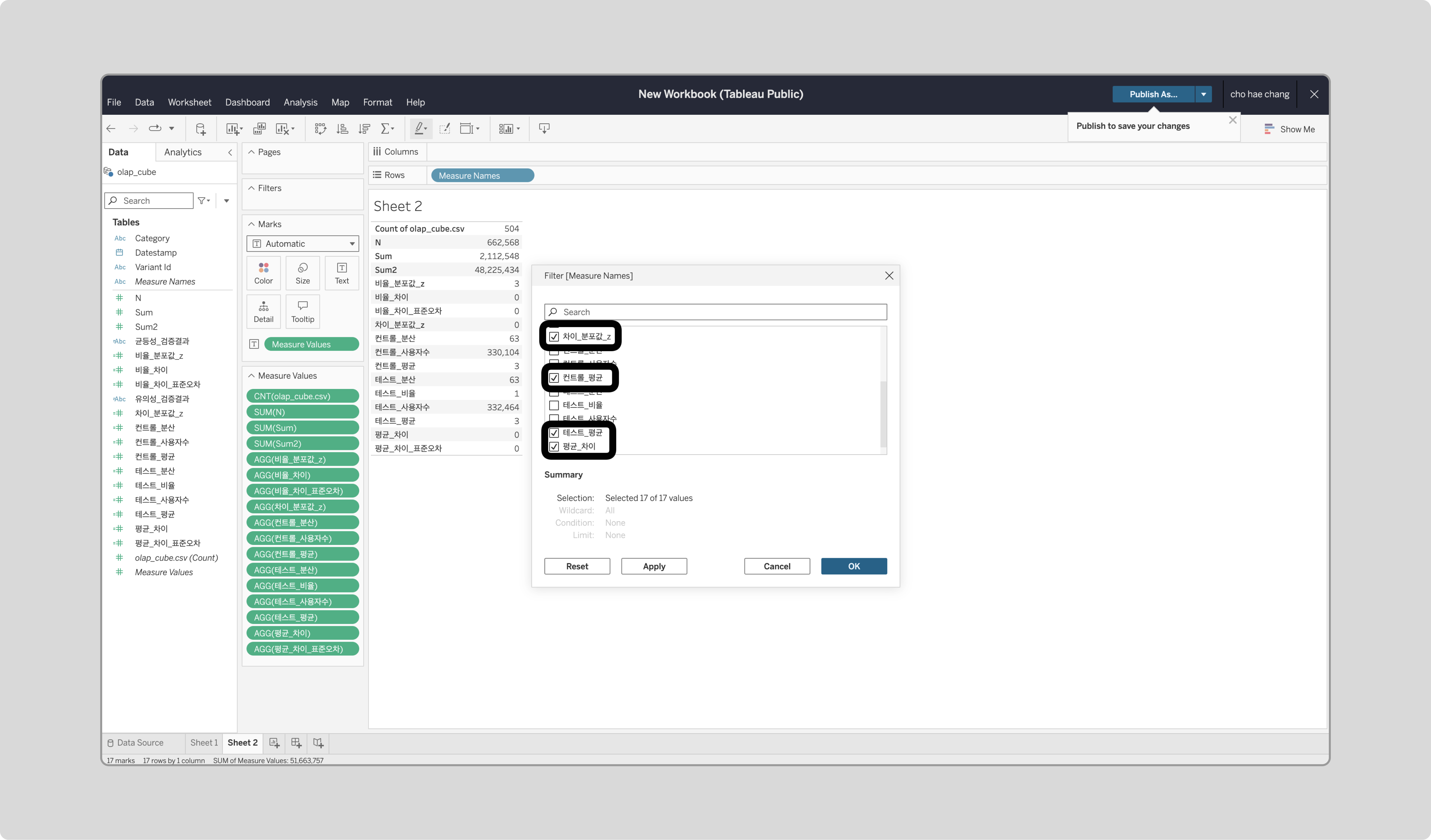
‘Measure Values’를 우클릭해 Filter로 들어가 ‘컨트롤_평균’, ‘테스트_평균’, ‘평균_차이’, ‘차이_분포값_z’를 체크합니다.
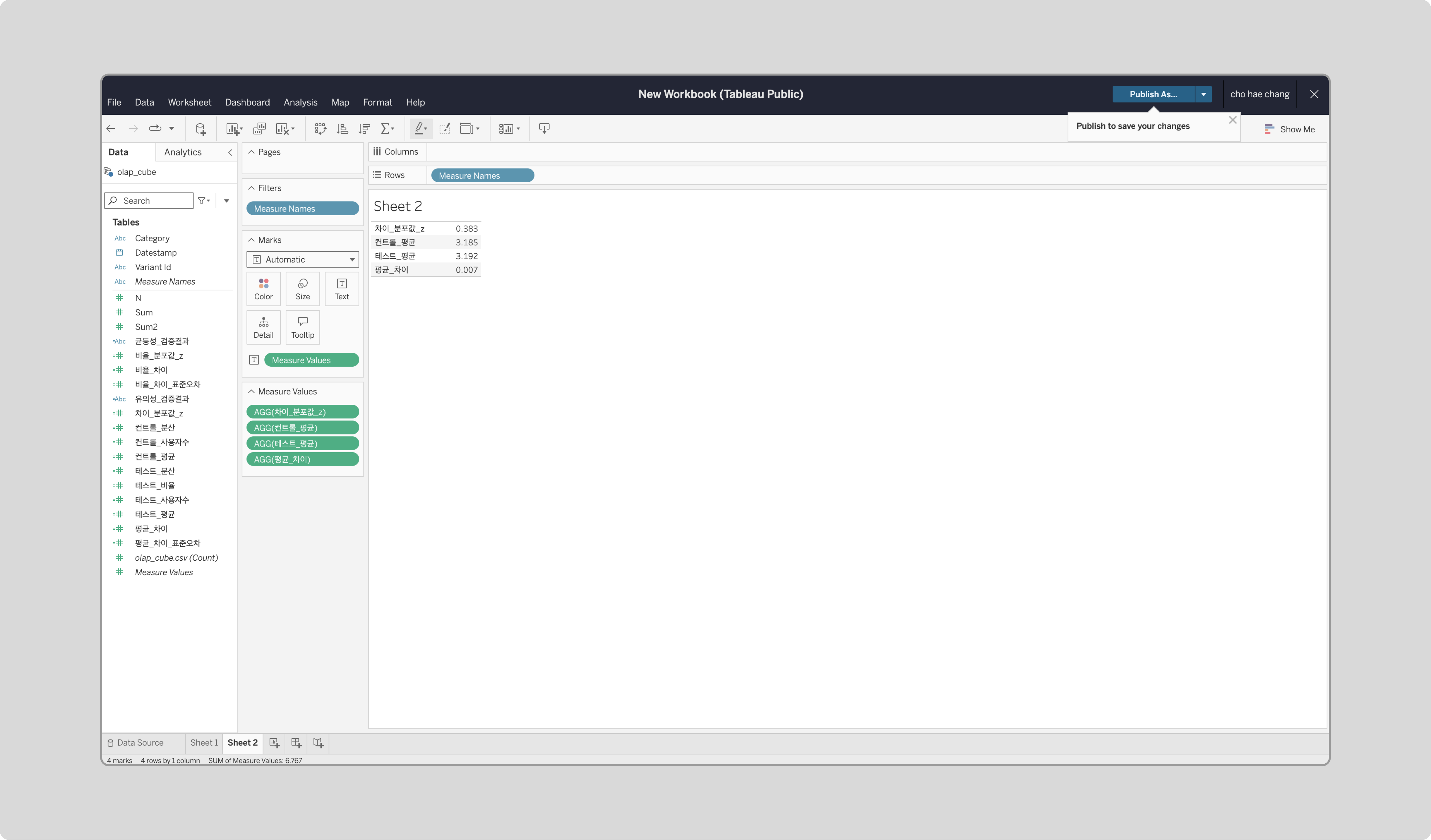
-
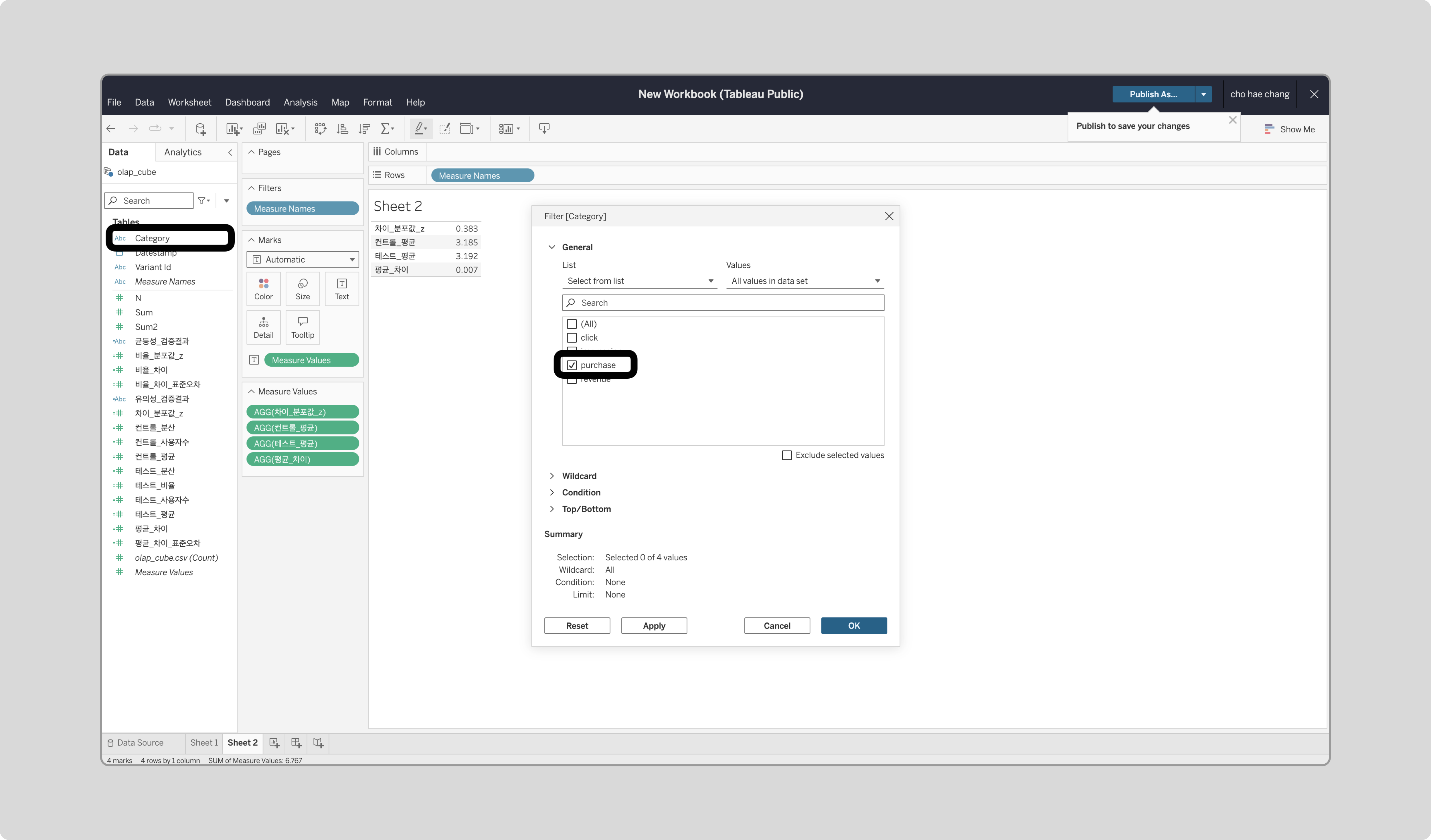
‘Category’를 Filters에 드래그하고, purchase를 체크합니다.
-
‘유의성_검증결과’를 Marks의 Color에 드래그합니다.
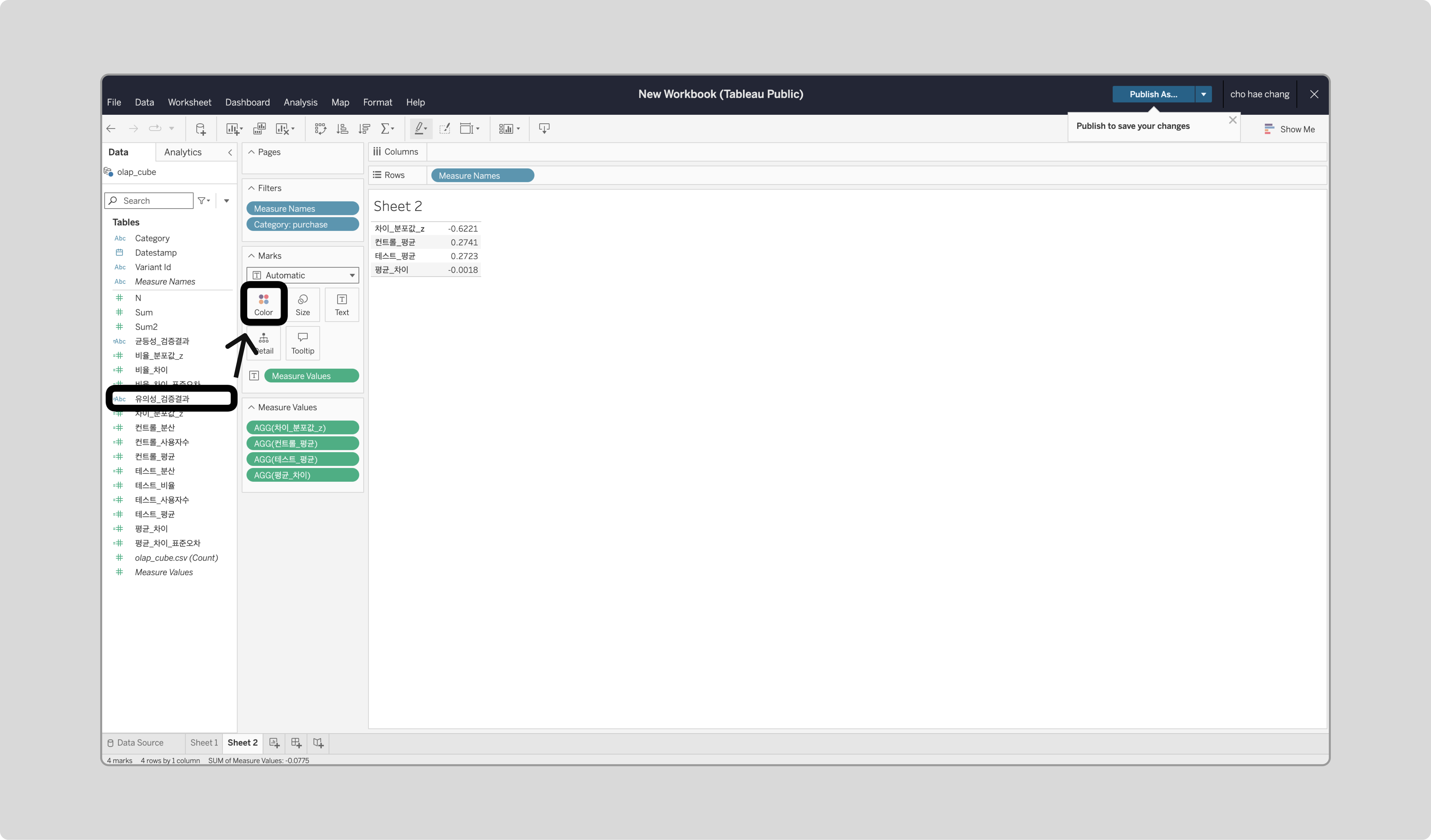
결과 분석
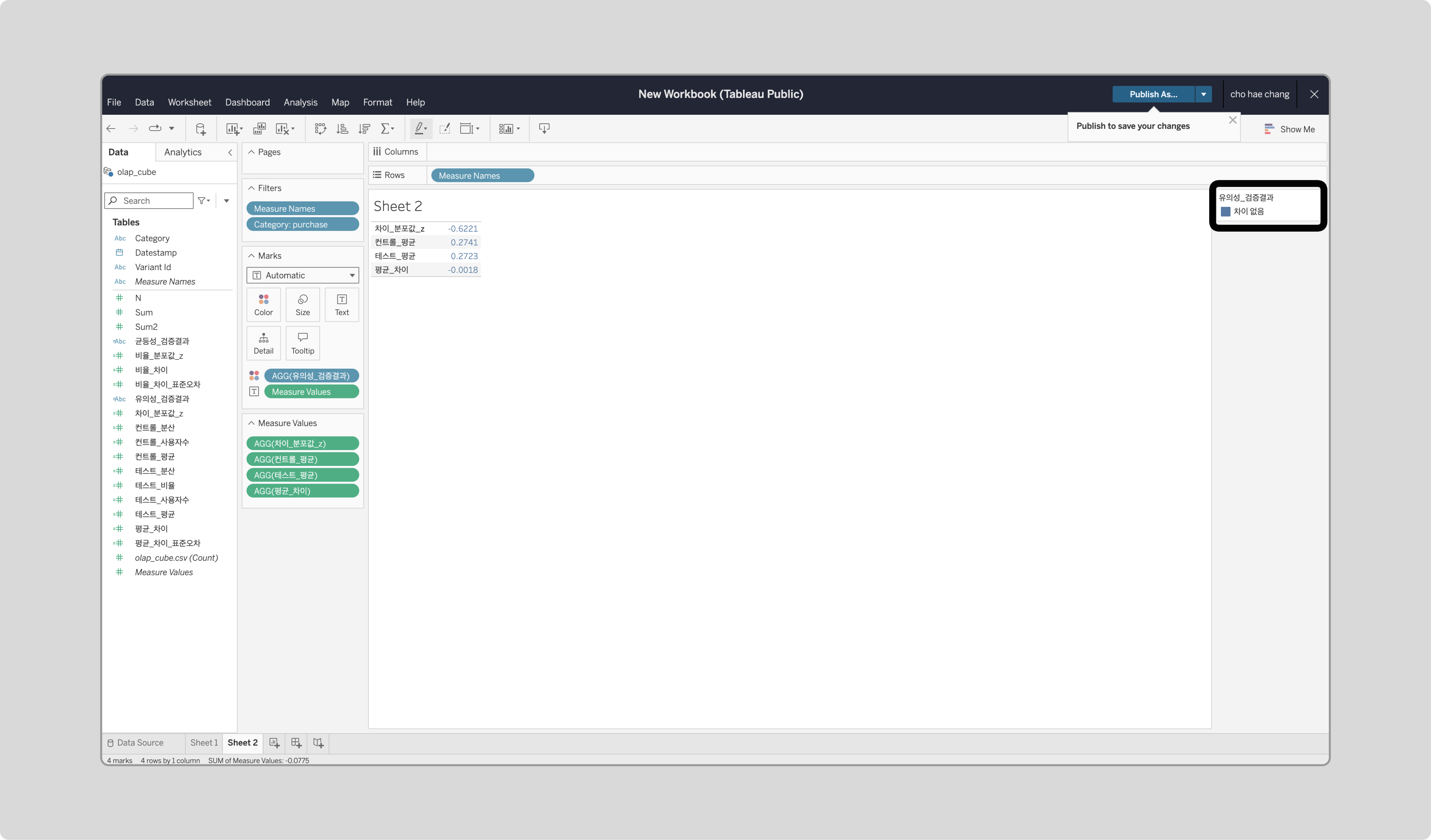
시각화된 데이터를 통해 test와 control 그룹의 평균 차이를 비교할 수 있습니다.
- Test 우세는 팝업이 긍정적인 영향을 미쳤음을 의미합니다.
- Control 우세는 오히려 부정적인 영향을 주었을 가능성을 나타냅니다.
- 차이 없음은 팝업이 기대한 효과를 미치지 않았음을 의미하므로, 개선이 필요할 수 있습니다.
또한, 다양한 퍼널 지표로 Category를 교체하며 분석하면 팝업이 구매 여정의 각 단계별로 어떤 영향을 미치는지 더 폭넓게 파악할 수 있습니다.